Нередко мы слышим от коллег вопросы о том, как искусственный интеллект влияет на тестирование ПО и какие новые подходы в тестировании появились для оптимизации расходов и ускорения процессов. В этой статье сосредоточимся на самых основных и эффективных практиках, а также разберём ключевые риски, в том числе нетехнического характера.
Наш принцип прост: мы принципиально не предлагаем клиентам «нейросеть в тестировании» ради моды. Все нижеперечисленные решения мы сначала обкатывали на собственных проектах. То, что не приносило результата, мы отсеивали, а инструменты с измеримым эффектом и успешно прошедшие четыре слоя контроля внедряли для заказчиков – с их одобрения и предварительно согласовав обработку данных.
Мы пришли к выводу, что искусственный интеллект не думает за QA‑инженера и не понимает продукт так, как понимает его человек – сколько бы спецификаций, схем и снимков экрана в него ни загрузили. Зато он эффективно берёт на себя рутину и помогает управлять большими объёмами данных. Но без грамотного управления ИИ может привести к нежелательным и даже печальным результатам.
Проверьте по двум критериям, стоит ли поручать задачу ИИ?
Прежде чем поручить задачу модели, мы оцениваем её по двум ключевым параметрам – не по «крутости» модели или хайповости подхода, а по реальному эффекту:
- Цена пропущенной ошибки. Что будет, если инженер не заметит недочёт? Например, некорректный набор тестовых данных можно перегенерировать за минуту, а вот пропущенный сценарий приёмки в платёжном модуле может привести к финансовым потерям для клиентов и последующим разбирательствам.
- Сложность проверки результата. Сколько времени и ресурсов потребуется, чтобы убедиться, что ИИ не выдумала ответ? Если проверка занимает меньше времени и сил, чем самостоятельное выполнение задачи, – решение оправдано. Если же проверять результат так же долго, как делать работу вручную, то игра не стоит свеч.
Мода на инструменты приходит и уходят, а правильные вопросы остаются: вот что действительно важно.

Четыре слоя контроля, без которых мы не отдаём задачи нейронке
Чтобы решить, можно ли доверить задачу искусственному интеллекту, мы проводим четыре последовательных слоя проверки – каждый отвечает за свой аспект безопасности и корректности.
Задача проходит все четыре этапа. Если не проходит любой из слоёв – к клиенту она не идёт.
Первый слой проверки – юридический, и его часто недооценивают. Согласно 152‑ФЗ, обработкой персональных данных считается любая операция с ними, включая анализ – неважно, выполняет её человек или алгоритм. Получается, загрузка клиентских данных в стороннюю нейросеть уже считается обработкой со всеми вытекающими последствиями. Поэтому ещё до формулировки первого запроса мы определяем, какие данные допустимо передавать модели и в каком контуре их можно использовать. Остальные три слоя – про среду, про обязательную проверку человеком и про измерение эффекта уже после внедрения.
Подробно разбираем матрицу решений
Левый нижний угол матрицы
Ошибиться не страшно, проверить дёшево. Здесь ИИ работает как добросовестный помощник, а инженер лишь сверяет результат.
Подготовка синтетических тестовых данных
риск низкий
Это, пожалуй, единственная задача, где мы почти спокойны. Реальные данные клиентов в тестах сегодня – прямой путь под санкции, поэтому постоянно нужна синтетическая информация: для регрессии, нагрузки и редких сценариев.
Нейросети задают структуру – поля, типы, ограничения, правила предметной области (валидный по контрольной сумме идентификатор, дата рождения не из будущего, сумма заказа кратна позициям), – а на выходе получают набор данных нужного объёма. Результат проверяют автоматически: прогоняют через схему и валидаторы – данные либо подходят, либо нет. Если структура базы чувствительна, используют локальную модель в контуре. Единственная типичная проблема – ИИ «причёсывает» данные и теряет разнообразие; её решают, явно задавая требуемые распределения в запросе.
Оформление и приведение в порядок баг‑репортов
риск низкий
Инженер нашёл дефект, записал голосовое сообщение и сделал пару снимков экрана. Превратить это в нормальный тикет – с шагами, ожидаемым и фактическим результатом, черновиком критичности и данными об окружении – механическая работа, которую никто не любит. Проверка тут бесплатная: автор видел баг и за пять секунд скажет, исказила ли нейросеть суть или нет. Бонусом получаем единообразие тикетов и то, что обычно забывают приложить: версию сборки, предусловия, шаги до проблемы. Критичность предлагает нейросеть, но финальную метку ставит инженер.
Заготовки кода для автотестов
риск низкий–средний
Скелеты объектов страниц (шаблон Page Object), фикстуры, фабрики данных, параметризованные таблицы, заготовки клиента к API – всё это скучно писать, но легко проверить: код либо проходит сборку и статический анализ, либо нет. Важно отделять: структуру можно доверить модели, а смысл оставляем за собой. Просьба «напиши заготовку объекта страницы для этого экрана» безопасна, а вот «напиши тесты на оплату» – уже из другой категории.
Перекладка форматов и переводы
риск низкий
Чек‑лист – в формализованные сценарии (Gherkin), таблицу решений – в параметризованные кейсы, документацию – с русского на английский для зарубежного заказчика и обратно. Это просто перекладка из формата в формат без потери смысла: проверить можно за минуту – исходник ведь перед глазами.
Группировка сбоев и разбор журналов
риск низкий–средний
Прогон выдал две сотни ошибок. Раньше инженер вручную разбирался, в чём дело, и видел: на самом деле проблем всего три, просто они повторились в разных тестах. Нейронка же сама группирует похожие сбои: 140 ошибок случились из‑за таймаута на сервере, 50 – потому что сменился локатор, а 10 – это настоящие дефекты. Дальше проверяют выборочно: берут по одному примеру из каждой группы.
Полностью полагаться на такую группировку нельзя: среди «одинаковых» сбоев порой прячется что‑то серьёзное. Но как первый шаг, чтобы разобрать кучу ошибок, этот подход годится. К тому же он помогает привести в порядок и другие вещи: сделать названия кейсов единообразными, обновить журнал изменений в тест‑репозитории, привести в норму старую документацию.
Середина матрицы
Цена ошибки уже немалая, а на проверку нужно время – вот почему без человека не обойтись. Зато скорость и охват растут так, что отказаться от этого в 2026 году – всё равно что сознательно тормозить развитие.
Проектирование тест‑кейсов по требованиям
риск средний
Модели передают пользовательскую историю или фрагмент спецификации – на выходе получается структурированный черновик: основной сценарий, граничные значения и негативные проверки, в том числе каверзные. На старте проекта это экономит, по нашим данным, около половины времени на подготовку. Исследования показывают, что генерация кейсов из спецификаций даёт около 87 % валидных кейсов – звучит отлично. Но стоит помнить: оставшиеся 13 % как раз и несут главную опасность.
Главная ловушка – «галлюцинация намерения». Если в документации есть пробелы, ИИ не задаст вопрос и не укажет на проблему – а просто выдумает бизнес‑логику и допишет под неё убедительные сценарии. Был случай: спецификация по скидкам оказалась неполной. Нейросеть решила, что скидки суммируются, и сгенерировала под это красивые кейсы. А в продукте скидки не суммировались – полчаса ушло на проверку несуществующей логики. Объём работы можно отдать модели, но контекст и финальное решение должен определять человек.
Генерация автотестов
риск средний
ИИ преобразует ручные кейсы или спецификацию в заготовки для Playwright, Cypress, pytest – со структурой, шагами и черновиками проверок. Дальше автоматизатор дорабатывает: исправляет локаторы, добавляет осмысленные проверки, устраняет нестабильность.
Тут кроется одна хитрость – видимость покрытия: сгенерированный набор тестов красиво светится зелёным, но если заглянуть в сами проверки, то половина из них сводится к «убедиться, что страница не пустая». Тест проходит всегда – потому что по сути ничего не проверяет. Поэтому в сгенерированных тестах мы сначала смотрим не на сам факт прохождения, а на то, что именно они проверяют.
Самовосстановление локаторов
риск средний
Раньше, если на клиентской части меняли идентификатор кнопки, половина тестов сразу переставала работать. Приходилось в спешке всё исправлять. Сейчас всё иначе: когда тест падает, агент анализирует структуру страницы (DOM). Например, видит: идентификатор другой, но кнопка по‑прежнему в блоке оплаты и подписана «Купить» – и тест продолжает работать. Благодаря этому расходы на поддержку снижаются – в нашей практике примерно на 40 %.
Но есть один важный нюанс, о котором редко говорят. Самовосстановление может сыграть злую шутку: оно способно замаскировать настоящий дефект. Допустим, элемент пропал не потому, что его переименовали, а потому что случайно убрали из вёрстки. В таком случае «починенный» тест покажет, что всё в порядке, – и настоящая проблема останется незамеченной. Поэтому агент у нас не вносит правки автоматически. Он лишь предлагает варианты, а человек проверяет и решает, что делать.
Регрессия по критичности изменений
риск средний–высокий
Когда в наборе тысячи тестов, а релиз только вышел, полная регрессия превращается в пытку, а приоритизация на глаз – в лотерею: можно запросто получить инцидент в проде.
Модели передают историю падений, свежие изменения в коде и данные мониторинга – она формирует набор тестов по уровню риска: проверяет только то, что действительно могло сломаться. Пока кто‑то запускает полный прогон на три часа, вы даёте заключение за сорок минут.

Риск пропустить важный тест всё же есть. Решается это просто: полную регрессию не отменяют – её переносят на ночь или выходные по расписанию.
Анализ первопричин и сортировка дефектов
риск средний
Когда в трекер поступает множество тикетов, человек видит лишь симптомы. ИИ сопоставляет журналы с шагами воспроизведения, группирует похожие дефекты и помогает разобраться в первопричинах. Вместо отчёта «у нас 50 дефектов» руководитель получает чёткую картину: «система деградирует в модуле оплаты из‑за конфликта типов в API – вот пять связанных кейсов». Благодаря этому среднее время локализации дефекта сокращается в два‑три раза. Первопричину предполагает нейронка, а подтверждает – инженер.
Контроль изменений в API и поддержка документации
риск средний
По описанию интерфейса (OpenAPI/Swagger) искусственный интеллект формирует проверки запросов и ответов на соответствие контракту. Сюда же относятся тест‑планы и отчёты – из сырых заметок, чек‑листов, идей для исследовательского тестирования. Идеи безопасны: это всего лишь предложения, а не готовые решения. Исполняет и оценивает их человек.
Правый верхний угол матрицы
Либо ошибиться дорого, либо проверить так же тяжело, как сделать самому. В таких случаях ИИ в QA – всего лишь ассистент, а последнее слово всегда за человеком.
- Финальная приёмка и решение о выпуске. Это ответственность, а ответственность не делегируется роботу. ИИ готовит сводку, но заключение даёт тестировщик.
- Удобство и продуктовое чутьё. искусственный интеллект не скажет: «Этот путь к корзине раздражает» или «Здесь пользователь растеряется» – он не чувствует неудобств. Опаснее всего даже не молчание, а ложная уверенность: получили вывод, что всё в порядке и расслабились.
- Закрытые данные в публичных зарубежных сервисах. Загрузить внутреннюю архитектуру или клиентские данные в публичный иностранный сервис – нарушение 152‑ФЗ. Если данные чувствительные, используйте только корпоративный сервис с хранением в РФ либо локальные модели в своём контуре.
- Высокорисковые домены. Платёжные операции, медицина, промышленный софт, где цена сбоя – деньги или жизни. Черновик кейсов можно сгенерировать, но доверять нейросети решение нельзя.
- Стратегия тестирования и оценка продуктовых рисков. Работа с контекстом, которого у нейронки нет: историей проекта, политикой, реальными болевыми точками бизнеса. Шаблонная стратегия выглядит убедительно лишь до первого столкновения с реальностью.
- Глубокая доменная логика на дырявой документации. Чем больше пробелов в описании, тем увереннее ИИ заполнит их правдоподобной ерундой. Здесь она опаснее всего – ошибается очень убедительно.
- Безопасность как замена аудиту и проверке на проникновение. Первый проход по типовым уязвимостям – пожалуйста. Заключение «защищено» – нет.
Общее правило, вытекающее из всего сказанного: если проверить результат дороже, чем сделать самому, – не передавайте это ИИ. Звучит банально, но это совет, который спасёт от провальных внедрений.
Как мы используем ИИ при подготовке нагрузочных тестов
Здесь остановимся подробнее, так нагрузочное тестирование с помощью ИИ хорошо иллюстрирует наш подход: от внутренней обкатки до запуска у клиента.
Классическое нагрузочное тестирование в России обходится дорого: каждый раз, чтобы проверить, выдерживает ли продукт нагрузку, приходится привлекать подрядчика или выделенного инженера. Специалист разворачивает стенд, пишет профили нагрузки, проводит тесты, собирает данные из консоли и ещё день тратит на подготовку понятного отчёта с выводами.
Рассмотрим популярный движок k6: «из коробки» он не предоставляет ни нормального визуального отчёта, ни анализа. Для получения графиков нужно развернуть отдельное хранилище метрик и написать обвязку. По умолчанию доступны лишь числовые данные в консоли.
Мы создали поверх k6 переиспользуемую обвязку. Сначала несколько месяцев тестировали её на собственных продуктах, а затем – с согласия клиентов и после анализа их систем – стали предлагать им. Предварительно разбирались, какие данные допустимо использовать.
Логика такая:
- Профили нагрузки лежат в конфигурации: дымовая, лёгкая, средняя, тяжёлая. Нужна нарастающая, трапециевидная, пиковая или постоянная нагрузка – берётся готовый профиль или дописывается свой.
- Сценарии задаются отдельно, кодом: какие конечные точки API задействуются и в каком порядке.
- Пороги – это целевые показатели (SLA). Например, если раздел должен открываться за 4 секунды, выставляется соответствующий порог. Прогон покажет, уложились ли в него – а то бывает, что открывается за 12 секунд.
- Запуск выполняется одной командой или по событию в конвейере. Прогнали нужным профилем – получили отчёт.
- Отчёт формируется автоматически: включает окружение, дату прогона, инструмент, конфигурацию, число запросов и долю успешных, графики пропускной способности и нарастания пользователей, перечень задействованных конечных точек.
- Выводы генерирует нейросеть: она анализирует метрики и выдаёт понятные формулировки – где произошла деградация, где достигнут порог, где возникли ошибки сервера. Важный момент для бюджета: для такого анализа не нужна самая дорогая модель – с задачей справится и более простая, с достаточным контекстом.
Переиспользовать решение на новом проекте можно быстро: достаточно поменять базовый адрес и авторизацию через переменные окружения, адаптировать сценарий под свои конечные точки, выставить целевые показатели и, при желании, настроить оформление отчёта под бренд заказчика в конфигурации. День на адаптацию – и дальше нагрузку запускают по кнопке, без привлечения подрядчика каждый раз.
По времени разница следующая. Раньше опытный QA-инженер тратил около двух рабочих дней, чтобы получить осмысленный нагрузочный отчёт с анализом: день – на постановку и сбор данных, ещё день – на анализ и оформление. С применением ИИ весь цикл (прогон плюс отчёт) укладывается в два часа. Поэтому нагрузку можно проверять не один раз перед большим релизом, а хоть в каждом спринте.
Честная граница применимости
Для среднего и средне‑крупного веба, мобильных приложений и серверных частей обвязка работает отлично: например, портал с требованием «каталог грузится за N секунд» тестируется быстро и эффективно.
А вот сложную систему из десятка подпроектов, тесно связанных с разными платформами и с нетривиальной авторизацией, так просто не протестировать — здесь нужна ручная работа для каждого компонента.
Поэтому перед запуском мы всегда анализируем стек: на чём построена система, как устроена авторизация и какие элементы действительно стоит нагружать. Цифры в отчёте достоверные (это данные от k6), но пороги задаёт QA-инженер, а выводы ИИ – лишь первый этап анализа, который обязательно подтверждает человек.
Объясняем на цифрах: какой эффект даёт ИИ в QA?
Бизнес словам не верит. Вот формула окупаемости (возврата инвестиций), которую можно применить к вашему проекту:
Окупаемость (%) = (Годовая экономия − Годовые затраты на ИИ) / Годовые затраты × 100%
Годовая экономия = (Часы «до» − Часы «после») × Ставка часа × Раз в год
Годовые затраты = Подписка/токены за год
+ Разовая настройка × Ставка (распределённая по числу прогонов)
+ Часы на проверку результата × Ставка × Раз в год
+ Обучение команды
Главное, что упускают в красивых презентациях, – скрытые затраты. Их три, и они съедают выгоду:
- Время на проверку. Это самая большая статья расходов: ИИ сгенерировала за минуту, а инженер проверял два часа – и эти два часа идут в расчёт.
- Настройка и отладка формулировок. Разовая затрата, которая распределяется на все будущие прогоны.
- Контроль за нейросетью и стоимость инцидента. Это премия за риск: что будет, если БАГ пропустят? На высокорисковых задачах эта статья перевешивает всё остальное – поэтому такое не делегируют.
Расчёты по российским ставкам (полная стоимость часа): QA Middle – около 1 200 ₽/ч, AQA – от 1 500 ₽/ч (для senior – 2 500 ₽/ч). Цифры округлены – можете подставить свои данные.
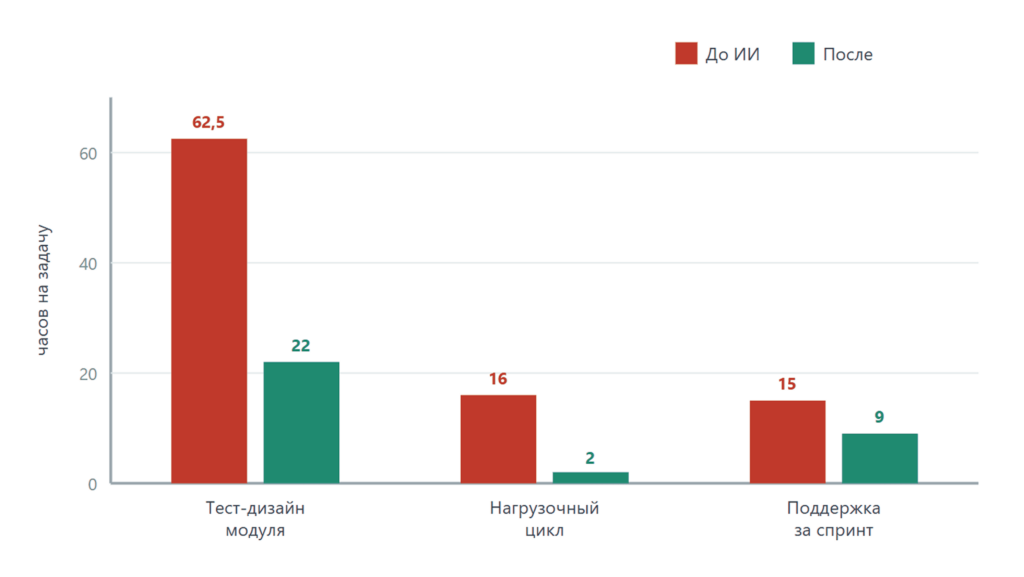
- Проектирование тест‑кейсов нового модуля: 40 пользовательских историй, всего около 250 кейсов.
Было: 250 × 15 мин = 62,5 ч × 1 200 ₽ = 75 000 ₽ за модуль.
Стало: генерация – около 1 ч, проверка и правки – 250 × 5 мин ≈ 21 ч, плюс час на формулировки, итого ≈ 22 ч × 1 200 ₽ = 26 400 ₽. Затраты на токены – 300–800 ₽.
Экономия: ≈ 48 000 ₽ за модуль, сокращение времени на 65%. При восьми модулях в год – около 384 000 ₽. Учитываем, что 13% кейсов невалидны – именно на них уходит дополнительное время проверки.
- Цикл нагрузочного тестирования при подготовленной инфраструктуре.
Было: около 2 рабочих дней (16 ч) на постановку, прогон и анализ × 2 500 ₽ = 40 000 ₽ за цикл (каждый раз с нуля).
Стало: около 2 ч на прогон с отчётом × 2 500 ₽ = 5 000 ₽. Анализ от простой модели обходится почти бесплатно.
Экономия: ≈ 35 000 ₽ за цикл. При тестировании раз в спринт (24 раза в год) – около 840 000 ₽. Минус разовая адаптация под проект – примерно день работы (20 000 ₽). Окупаемость – в первом квартале.
- Поддержка автотестов (самовосстановление локаторов), набор – около 800 тестов.
Было: примерно 15 ч/спринт на починку локаторов и устранение нестабильности × 24 спринта = 360 ч/год × 1 500 ₽ = 540 000 ₽.
Стало: самовосстановление сокращает ручную починку на ~40%.
Экономия: около 216 000 ₽/год. Затраты – инфраструктура агента и проверка предложенных правок.
В первых двух примерах деньги – лишь половина. Вторая половина в том, что джун не выгорает на двухсотом однотипном кейсе, а нагрузочное тестирование перестаёт быть пугающим – его можно проводить чаще. Узкое место выявляется в спринте, а не за ночь до релиза.
Сводная таблица по передаче QA-задач нейросетям
| Задача | Режим | Типовой эффект | Риск | Слои контроля |
|---|---|---|---|---|
| Синтетические данные | Передать | Часы в минуты, без риска утечки | низкий | 1, 3 |
| Оформление баг‑репортов | Передать | Единообразие, минус рутина | низкий | 3 |
| Заготовки автотестов | Передать | Минус ручная рутина | низкий/средний | 2, 3 |
| Группировка сбоев и журналов | Передать | Минус часы анализа | низкий/средний | 3 |
| Проектирование тест‑кейсов | Ускорить | −50–60% фазы подготовки | средний | 3, 4 |
| Генерация автотестов | Ускорить | Меньше ручного написания | средний | 3, 4 |
| Самовосстановление локаторов | Ускорить | −40% поддержки | средний | 3 |
| Регрессия по критичности изменений | Ускорить | Заключение за минуты | средний/высокий | 3, 4 |
| Анализ первопричин | Ускорить | Время локализации меньше в 2–3 раза | средний | 3 |
| Нагрузочное (k6 + анализ модели) | Ускорить | 2 дня → 2 часа за цикл | средний | 1, 3, 4 |
| Приёмка или решение о выпуске | Избегать | — | высокий | только человек |
| Удобство, продуктовое чутьё | Избегать | — | высокий | только человек |
| Закрытые данные в публичный сервис | Избегать | — | высокий | барьер на слое 1 |
| Платежи/медицина/ промышленность | Избегать | только ассистент | высокий | решение за экспертом |
Зоны повышенного риска
Красный флаг №1
Загрузка данных российских граждан в зарубежный сервис нарушает требование о локализации. Персональные и закрытые данные нужно обрабатывать либо на локальной модели в контуре компании, либо через корпоративный сервис с хранением в РФ.

152‑ФЗ – не страшилка, а чёткое законодательное требование. С 30 мая 2025 года штрафы за утечку персональных данных зависят от масштаба: при утечке от 1 000 человек штраф составит 3–5 млн ₽, от 10 000 человек – 5–10 млн ₽, а свыше 100 000 человек – 10–15 млн ₽. За утечку биометрических данных предусмотрен штраф 15–20 млн ₽. В случае повторной утечки назначается оборотный штраф – 1–3 % годовой выручки (не менее 20 млн ₽ и до 500 млн ₽).
Красный флаг №2
Умнее не значит меньше ошибается. По отчётам за 2025 год даже новые нейросети, ориентированные на пошаговые рассуждения, допускают ошибки в трети и даже половине случаев на фактических задачах. То есть переход на более дорогую и продвинутую модель сам по себе не снимает потребность в проверке.
Красный флаг №3
Видимость покрытия. Утверждения о 100% сгенерированных кейсов и 100% покрытия – совсем не одно и то же. Зелёный набор проверок, который ничего не проверяет, хуже его отсутствия: он усыпляет бдительность команды и ведёт к потере драгоценного времени.
Красный флаг №4
Ложная уверенность. Ссылка на то, что результат получен от продвинутой нейросети последнего поколения, – не аргумент, а потенциальный источник проблем. Без процесса проверки внедрение ИИ просто ускоряет и масштабирует баги. Особенно это касается, когда с ИИ взаимодействуют QA-джуны: им проще довериться выводу ИИ, чем оспорить его.
Как внедрить ИИ в тестирование без потерь?
Не пытайтесь браться за всё и сразу – разочаруетесь и бросите. Вот порядок, который сработал у нас:
- Сначала выберите одну задачу, которую можно отдать нейронке и протестируйте её на внутреннем или некритичном проекте, а не сразу на клиенте.
- Затем сделайте исходный замер: сколько часов это занимает сейчас. Без замера не получится посчитать окупаемость и доказать ценность решения.
- Проведите работу с ИИ и снова замерьте время – уже с учётом проверки. Это и будет реальная цифра.
- Посчитайте окупаемость по формуле и проверьте процесс выполнения задачи через четыре слоя проверок.
- Только то, что показало себя эффективно, переносите на клиента – с его согласия и в рамках согласованного перечня допустимых данных.
- Переходите к режиму «Ускорить» только после того, как уверенно освоите режим «Передать». Режим «Избегать» пока оставьте – сначала наработайте опыт.
- Железное правило: ИИ предлагает варианты, окончательное решение принимает человек.
- Заранее решите вопрос с данными: определите, какие данные можно передавать и в какой контур.
А какой вывод?
Искусственный интеллект в тестировании – не замена QA-инженера, а инструмент для ускорения. ИИ берёт на себя рутинные задачи и помогает обрабатывать большие объёмы данных, но не понимает продукт и не несёт ответственности за его выпуск. Реальная польза появляется, когда задача поставлена корректно, а результат проходит многоуровневый контроль — иначе есть риск масштабировать ошибки и столкнуться с крупными проблемами.
В «Лаборатории качества» мы обкатываем ИИ‑практики на внутренних проектах, тщательно измеряем эффект и прогоняем решения через четыре слоя контроля. Только проверенные инструменты, с согласия заказчика и с соблюдением требований безопасности, внедряем в клиентские продукты – чтобы ускорить релизные циклы и снизить стоимость разработки.
Хотите прикинуть, какие из наших подходов дадут максимальный эффект на вашем стеке? Запишитесь на бесплатную консультацию по внедрению ИИ в QA‑процессы.
Тренды и фишки из мира IT,
экспертные статьи и всё о тестировании.










