
Самый лучший способ оценить, хорошо ли мы протестировали продукт – проанализировать пропущенные дефекты. Те, с которыми столкнулись наши пользователи, внедренцы, бизнес. По ним можно многое оценить: что мы проверили недостаточно тщательно, каким областям продукта стоит уделить больше внимания, какой вообще процент пропусков и какова динамика его изменений. С этой метрикой (пожалуй, самой распространённой в тестировании) всё хорошо, но… Когда мы выпустили продукт, и узнали о пропущенных ошибках, может быть уже слишком поздно: на “хабре” появилась про нас гневная статья, конкуренты стремительно распространяют критику, клиенты потеряли к нам доверие, руководство недовольно.
Чтобы такого не происходило, мы обычно заранее, до релиза, стараемся оценивать качество тестирования: насколько хорошо и тщательно мы проверяем продукт? Каким областям не хватает внимания, где основные риски, какой прогресс? И чтобы ответить на все эти вопросы, мы оцениваем тестовое покрытие.
Зачем оценивать?
Любые метрики оценки – трата времени. В это время можно тестировать, заводить баги, готовить автотесты. Какую такую магическую пользу мы получаем благодаря метрикам тестового покрытия, чтобы пожертвовать временем на тестирование?
- Поиск своих слабых зон. Естественно, это нам нужно? Не чтобы просто погоревать, а чтобы знать, где требуются улучшения. Какие функциональные области не покрыты тестами? Что мы не проверили? Где наибольшие риски пропуска ошибок?
- Редко по результатам оценки покрытия мы получаем 100%. Что улучшать? Куда идти? Какой сейчас процент? Как мы его повысим какой-либо задачей? Как быстро мы дойдём до 100? Все эти вопросы приносят прозрачности и понятности нашему процессу, а ответы на них даёт оценка покрытия.
- Фокус внимания. Допустим, в нашем продукте около 50 различных функциональных зон. Выходит новая версия, и мы начинаем тестировать 1-ю из них, и находим там опечатки, и съехавшие на пару пикселей кнопки, и прочую мелочь… И вот время на тестирование завершено, и эта функциональность проверена детально… А остальные 50? Оценка покрытия позволяет нам приоритезировать задачи исходя из текущих реалий и сроков.
Как оценивать?
Прежде, чем внедрять любую метрику, важно определиться, как вы её будете использовать. Начните с ответа именно на этот вопрос – скорее всего, вы сразу поймёте, как её лучше всего считать. А я только поделюсь в этой статье некоторыми примерами и своим опытом, как это можно сделать. Не для того, чтобы слепо копировать решения – а для того, чтобы ваша фантазия опиралась на этот опыт, продумывая идеально подходящее именно вам решение.
Оцениваем покрытие требований тестами
Допустим, у вас в команде есть аналитики, и они не зря тратят своё рабочее время. По результатам их работы созданы требования в RMS (Requirements Management System) – HP QC, MS TFS, IBM Doors, Jira (с доп. плагинами) и т.д. В эту систему они вносят требования, соответствующие требованиям к требованиям (простите за тавтологию). Эти требования атомарны, трассируемы, конкретны… В общем, идеальные условия для тестирования. Что мы можем сделать в таком случае? При использовании скриптового подхода – связывать требования и тесты. Ведём в той же системе тесты, делаем связку требование-тест, и в любой момент можем посмотреть отчёт, по каким требованиям тесты есть, по каким – нет, когда эти тесты были пройдены, и с каким результатом.
Получаем карту покрытия, все непокрытые требования покрываем, все счастливы и довольны, ошибок не пропускаем…
Ладно, давайте вернёмся с небес на землю. Скорее всего, детальных требований у вас нет, они не атомарны, часть требований вообще утеряны, а времени документировать каждый тест, ну или хотя бы каждый второй, тоже нет. Можно отчаяться и поплакать, а можно признать, что тестирование – процесс компенсаторный, и чем хуже у нас с аналитикой и разработкой на проекте, тем больше стараться должны мы сами, и компенсировать проблемы других участников процесса. Разберём проблемы по отдельности.
Проблема: требования не атомарны.
Аналитики тоже иногда грешат винегретом в голове, и обычно это чревато проблемами со всем проектом. Например, вы разрабатываете текстовый редактор, и у вас могут быть в системе (в числе прочих) заведены два требования: «должно поддерживаться html-форматирование» и «при открытии файла неподдерживаемого формата, должно появляться всплывающее окно с вопросом». Сколько тестов требуется для базовой проверки 1-го требования? А для 2-го? Разница в ответах, скорее всего, примерно в сто раз!!! Мы не можем сказать, что при наличии хотя бы 1-го теста по 1-му требованию, этого достаточно – а вот про 2-е, скорее всего, вполне.
Таким образом, наличие теста на требование нам вообще ничего не гарантирует! Что значит в таком случае наша статистика покрытия? Примерно ничего! Придётся решать!
- Автоматический расчёт покрытия требований тестами в таком случае можно убрать – он смысловой нагрузки всё равно не несёт.
- По каждому требованию, начиная с наиболее приоритетных, готовим тесты. При подготовке анализируем, какие тесты потребуются этому требованию, сколько будет достаточно? Проводим полноценный тест-анализ, а не отмахиваемся «один тест есть, ну и ладно».
- В зависимости от используемой системы, делаем экспорт/выгрузку тестов по требованию и… проводим тестирование этих тестов! Достаточно ли их? В идеале, конечно, такое тестирование нужно проводить с аналитиком и разработчиком этой функциональности. Распечатайте тесты, заприте коллег в переговорке, и не отпускайте, пока они не скажут «да, этих тестов достаточно» (такое бывает только при письменном согласовании, когда эти слова говорятся для отписки, даже без анализа тестов. При устном обсуждении ваши коллеги выльют ушат критики, пропущенных тестов, неправильно понятых требований и т.д. – это не всегда приятно, но для тестирования очень полезно!)
- После доработки тестов по требованию и согласования их полноты, в системе этому требованию можно проставить статус «покрыто тестами». Эта информация будет значить значительно больше, чем «тут есть хотя бы 1 тест».
Конечно, такой процесс согласования требует немало ресурсов и времени, особенно поначалу, до наработки практики. Поэтому проводите по нему только высокоприоритетные требования, и новые доработки. Со временем и остальные требования подтянете, и все будут счастливы! Но… а если требований нет вообще?
Проблема: требований нет вообще.
Они на проекте отсутствуют, обсуждаются устно, каждый делает, что хочет/может и как он понимает. Тестируем так же. Как результат, получаем огромное количество проблем не только в тестировании и разработке, но и изначально некорректной реализации фич – хотели совсем другого! Здесь я могу посоветовать вариант «определите и задокументируйте требования сами», и даже пару раз в своей практике использовала эту стратегию, но в 99% случаев таких ресурсов в команде тестирования нет – так что пойдём значительно менее ресурсоёмким путём:
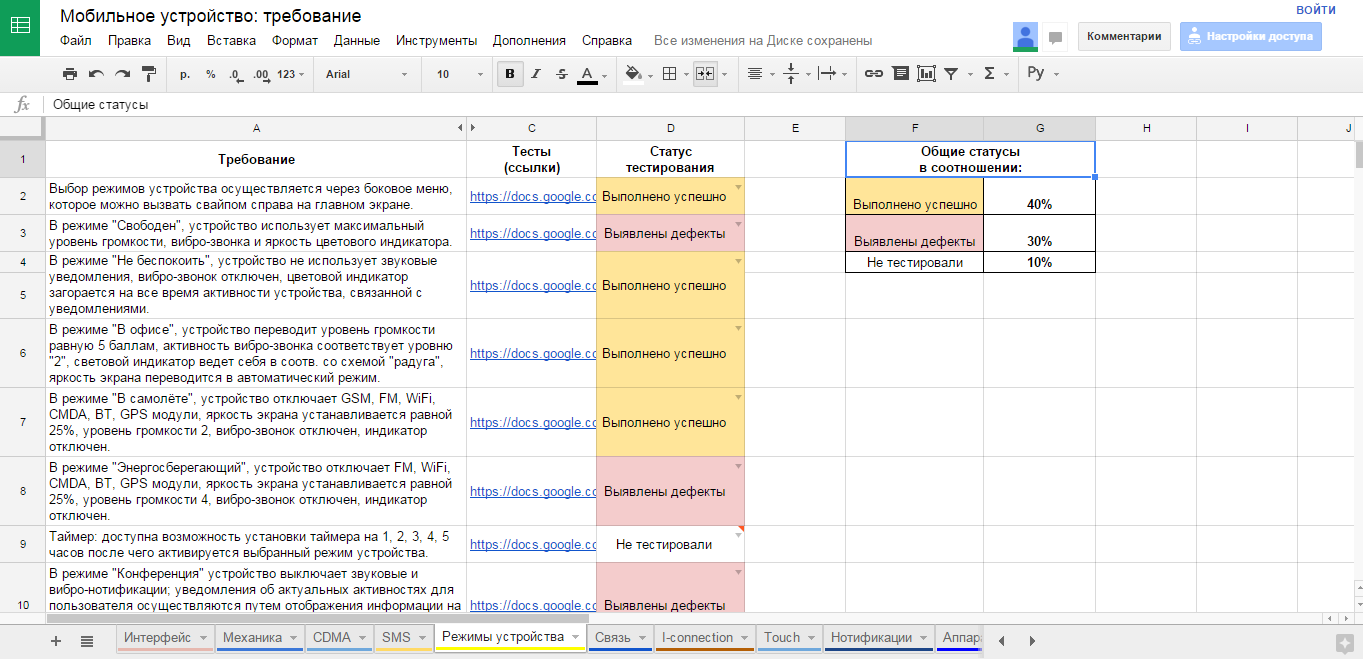
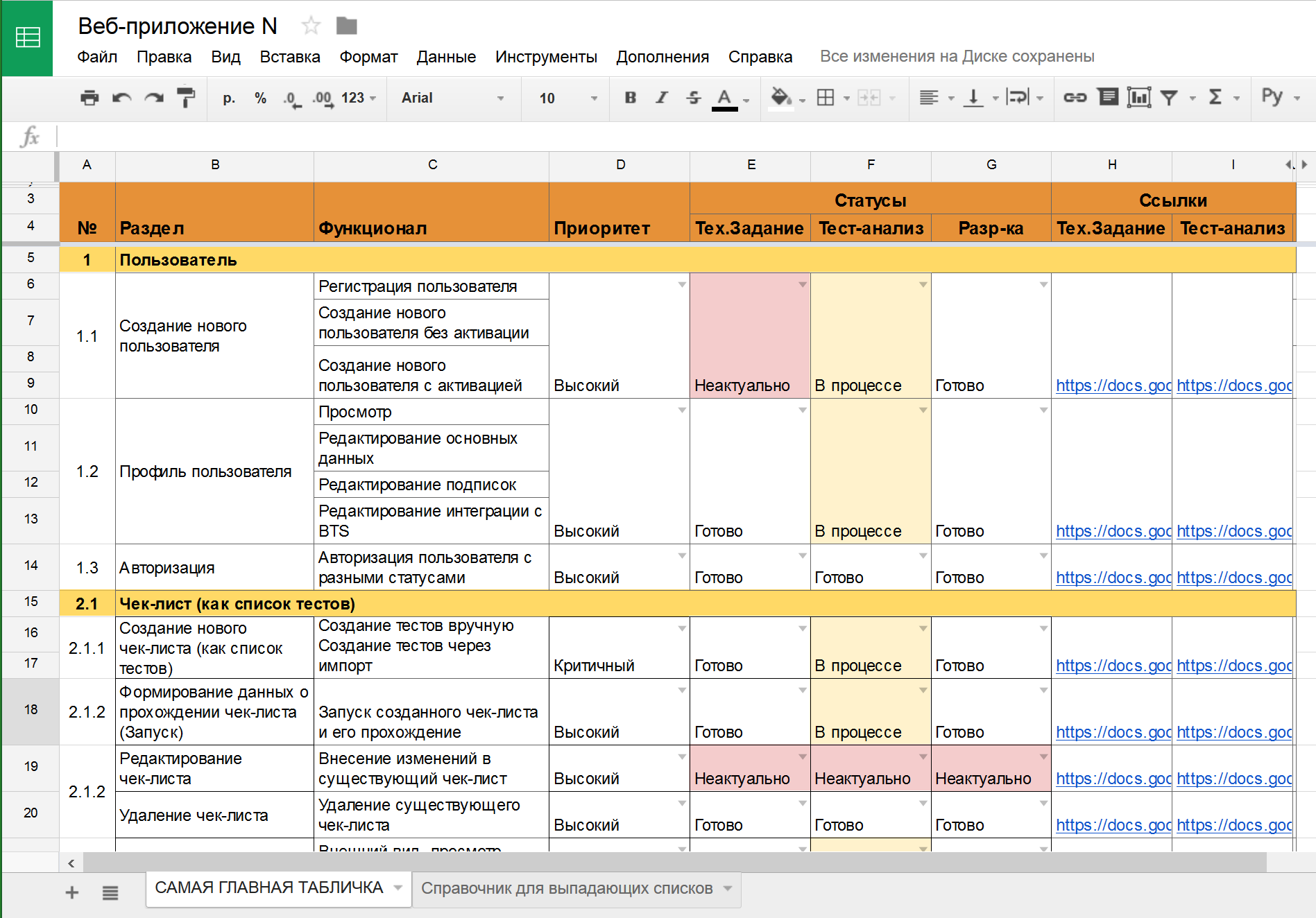
- Создаём фичелист (feature list). Сами! В виде google-таблички, в формате PBI в TFS – выбирайте любой, лишь бы не текстовый формат. Нам ещё статусы собирать надо будет! В этот список вносим все функциональные области продукта, и постарайтесь выбрать один общий уровень декомпозиции (вы можете выписать объекты ПО, или пользовательские сценарии, или модули, или веб-страницы, или методы API, или экранные формы…) – только не всё это сразу! ОДИН формат декомпозиции, который вам проще и нагляднее всего позволит не пропустить важное.
- Согласовываем ПОЛНОТУ этого списка с аналитиками, разработчиками, бизнесом, внутри своей команды… Постарайтесь сделать всё, чтобы не потерять важные части продукта! Насколько глубоко проводить анализ – решать вам. В моей практике всего несколько раз были продукты, на которые мы создали более 100 страниц в таблице, и это были продукты-гиганты. Чаще всего, 30-50 строк – достижимый результат для последующей тщательной обработки. В небольшой команде без выделенных тест-аналитиков большее число элементов фичелиста будет слишком сложным в поддержке.
- После этого, идём по приоритетам, и обрабатываем каждую строку фичелиста как в описанном выше разделе с требованиями. Пишем тесты, обсуждаем, согласовываем достаточность. Помечаем статусы, по какой фиче тестов хватает. Получаем и статус, и прогресс, и расширение тестов за счёт общения с командой. Все счастливы!
Но… Что делать, если требования ведутся, но не в трассируемом формате?
Проблема: требования не трассируемы.
На проекте есть огромное количество документации, аналитики печатают со скоростью 400 знаков в минуту, у вас есть спецификации, ТЗ, инструкции, справки (чаще всего это происходит по просьбе заказчика), и всё это выступает в роли требований, и на проекте уже все давно запутались, где какую информацию искать?
Повторяем предыдущий раздел, помогая всей команде навести порядок!
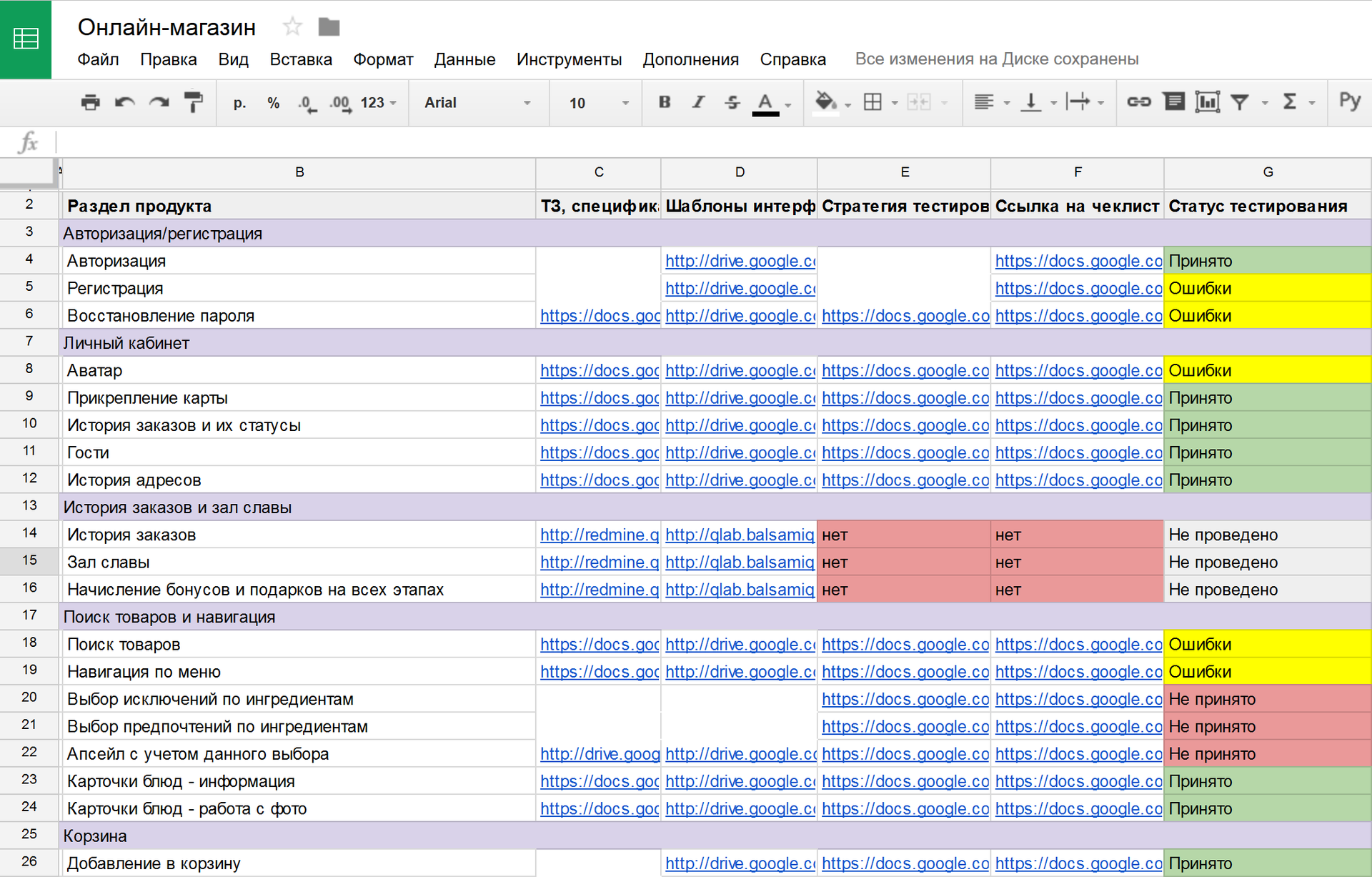
- Создаём фичелист (см. выше), но без детального описания требований.
- По каждой фиче собираем воедино ссылки на ТЗ, спецификации, инструкции, и прочие документы.
- Идём по приоритетам, готовим тесты, согласовываем их полноту. Всё то же самое, только благодаря объединению всех документов в одну табличку повышаем простоту доступа к ним, прозрачные статусы и согласованность тестов. В итоге, у нас всё супер, и все счастливы!
Но… Ненадолго… Кажется, за прошлую неделю аналитики по обращениям заказчиков обновили 4 разные спецификации!!!
Проблема: требования всё время меняются.
Конечно, хорошо бы тестировать некую фиксированную систему, но наши продукты обычно живые. Что-то попросил заказчик, что-то изменилось во внешнем к нашему продукту законодательстве, а где-то аналитики нашли ошибку анализа позапрошлого года… Требования живут своей жизнью! Что же делать?
- Допустим, у вас уже собраны ссылки на ТЗ и спецификации в виде фичелиста-таблицы, PBI, требований, заметок в Wiki и т.д. Допустим, у вас уже есть тесты на эти требования. И вот, требование меняется! Это может означать изменение в RMS, или задачу в TMS (Task Management System), или письмо в почте. В любом случае, это ведёт к одному и тому же следствию: ваши тесты неактуальны! Или могут быть неактуальны. А значит, требуют обновления (покрытие тестами старой версии продукта как-то не очень считается, да?)
- В фичелисте, в RMS, в TMS (Test Management System – testrails, sitechco, etc) тесты должны быть обязательно и незамедлительно помечены как неактуальные! В HP QC или MS TFS это можно делать автоматически при обновлении требований, а в google-табличке или wiki придётся проставлять ручками. Но вы должны видеть сразу: тесты неактуальны! А значит, нас ждёт полный повторный путь: обновить, провести заново тест-анализ, переписать тесты, согласовать изменения, и только после этого пометить фичу/требование снова как «покрыто тестами».
В этом случае мы получаем все бенефиты оценки тестового покрытия, да ещё и в динамике! Все счастливы!!! Но…
Но вы так много внимания уделяли работе с требованиями, что теперь вам не хватает времени либо на тестирование, либо на документирование тестов. На мой взгляд (и тут есть место религиозному спору!) требования важнее тестов, и уж лучше так! Хотя бы они в порядке, и вся команда в курсе, и разработчики делают именно то, что нужно. НО НА ДОКУМЕНТИРОВАНИЕ ТЕСТОВ ВРЕМЕНИ НЕ ОСТАЁТСЯ!
Проблема: не хватает времени документировать тесты.
На самом деле, источником этой проблемы может быть не только нехватка времени, но и ваш вполне осознанный выбор их не документировать (не любим, избегаем эффекта пестицида, слишком часто меняется продукт и т.д.). Но как оценивать покрытие тестами в таком случае?
- Вам всё равно нужны требования, как полноценные требования или как фиче-лист, поэтому какой-то из вышеописанных разделов, в зависимости от работы аналитиков на проекте, будет всё равно необходим. Получили требования / фичелист?
- Описываем и устно согласовываем вкратце стратегию тестирования, без документирования конкретных тестов! Эта стратегия может быть указана в столбце таблицы, на странице вики или в требовании в RMS, и она должна быть опять же согласована. В рамках этой стратегии проверки будут проводиться по-разному, но вы будете знать: когда это последний раз тестировалось и по какой стратегии? А это уже, согласитесь, тоже неплохо! И все будут счастливы.

Но… Какое ещё «но»? Какое???
Говорите, все обойдём, и да пребудут с нами качественные продукты!












Я не понимаю. Мы оцениваем покрытие ради каких-то метрик. Какие метрики мы получаем в результате такой оценки?