Юзабилити-тестирование… API?! Да, именно так. В своей предыдущей статье я говорила, что юзабилити является одной из ключевых характеристик хорошего API. Пришло время рассмотреть ряд важных вопросов: зачем, как и, главное, с помощью каких методов можно оценить эту характеристику для API.
Когда говорят о графических пользовательских интерфейсах (GUI), уже ни у кого не вызывает сомнения то, что юзабилити тестировать необходимо. Но давайте вспомним, что согласно международному стандарту ISO 9241-11 юзабилити – это степень, с которой продукт может быть использован определенными пользователями при определённом контексте использования для достижения определённых целей с должной эффективностью, продуктивностью и удовлетворенностью. Проще говоря, это та степень удобства использования продукта, с которой пользователь может без затруднений применить продукт и достичь своей цели. Как видим, в определении нет ни слова о менюшках, цвете кнопочек и размере шрифта. Мы можем оценить юзабилити для любого продукта, будь то мобильное приложение, утюг, или, в нашем случае, API.

В тестировании юзабилити API используются методы, относящиеся к техникам, разработанным в рамках направления под названием HCI (Human-Computer Interaction, человеко-компьютерное взаимодействие); они же применяются и для оценки GUI.
В данной статье я расскажу об основных и самых распространенных техниках. В целом, их можно разделить на два типа: аналитические и эмпирические (экспериментальные).
Аналитические методы
Аналитические методы оценки подразумевают исследование продукта и способов взаимодействия с ним, исходя из некоего экспертного знания. Грубо говоря, вы (тестировщик) или вся команда разработки каким-либо образом самостоятельно пытаетесь оценить и определить гипотетические проблемы с юзабилити.
1. Эвристическая оценка (Heuristic evaluation)

Простейшим методом проверки юзабилити является эвристическая оценка. Суть метода заключается в том, что существует некий набор критериев («эвристика»), которым продукт должен отвечать. Для оценки API можно определить абсолютно разный набор критериев: он будет зависеть от того, что из себя представляет ваш API (библиотека или REST сервис).
Например, в статье «Methods towards API Usability: A Structural Analysis of Usability Problem Categories» исследователи использовали для оценки юзабилити библиотеки большой набор эвристик:
- сложность – API не должен быть слишком сложным, гибкость и сложность должны быть сбалансированы;
- именование – используемые имена должны быть самодокументируемыми и логичными;
- читаемость – код должен быть читаемым (makeTV(Color) понятнее, чем makeTV(true));
- документация – она должна существовать и при этом содержать примеры;
- последовательность и общепринятые соглашения – дизайн должен быть последовательным и не разниться от метода к методу (порядок параметров, семантика);
- параметры методов и возвращаемые значения – параметров не должно быть слишком много, а возвращаемое значение должно четко обозначать результат выполнения метода;
- типы данных – используйте корректные типы, не заставляйте пользователя «приводить» типы (casting), избегайте использование строк;
- параллельный доступ – API должен корректно обрабатывать его;
- обработка ошибок и исключения – сообщения об ошибках должны содержать максимум необходимой информации, а исключения должны обрабатываться как можно ближе к тому месту, где они произошли;
- минимальный объем рабочего кода – чем меньше кода нужно писать пользователю, тем лучше;
- способ сделать правильно должен быть единственно-верным – API не должен позволять достичь цели несколькими способами.
Давайте подробнее рассмотрим некоторые из этих критериев на реальных примерах.
Критерий именования. В своей практике я постоянно встречаюсь с грустной ситуацией, возникающей при «погружении» нового тестировщика в тестирование системы: каждый раз джун приходит и говорит, что при использовании кода ФИАС произошла ошибка «Дома с таким-то кодом нет в системе». Я рекомендую использовать внутренний код дома в системе, на что джун делает большие глаза: «Нет такого параметра в запросе!» Приходится объяснять, что нужно использовать параметр FIASHouseGUID. Почему-то на заре проектирования сервисов параметр, содержащий GUID дома, обозвали FIASHouseGUID (код дома по ФИАС). При этом фактически можно использовать не только код ФИАС, но и внутренний код дома в системе. К сожалению, сервисы давно опубликованы и широко используются – следовательно, исправлять этот недочет уже слишком поздно.
Другой пример касается обработки ошибок. В одном из сервисов, который я тестирую, при изменении объекта распространена ошибка «Доступ запрещен для поставщика данных». Причин у этой ошибки может быть множество: нет правоустанавливающего документа, необходимого для операций над объектом; этот документ не находится в статусе «Размещен»; другая организация с привилегированными правами уже создала этот объект (а значит, организация пользователя не может его изменять). Причины разные, но текст ошибки одинаковый, и поэтому пользователь не имеет возможности понять, какая из причин «виновна» в этот раз.
Есть и более «суровые» эвристики оценки API. Чаще всего они специализированы на конкретных технических деталях разработки, например, критерии от Joshua Bloch. Для их оценки нужно уметь хотя бы немного программировать. Так, Microsoft провела обширное юзабилити-тестирование, выясняя, какой конструктор лучше использовать в API библиотек: конструктор по умолчанию с сеттерами и геттерами или конструкторы с обязательными параметрами. Результаты показали, что первый способ предпочтительнее; это стало эвристикой при разработке API.
2. Когнитивные измерения
Это особый вид критериев оценки юзабилити, выделенный в первую очередь для анализа синтаксиса, пользовательских интерфейсов и языков программирования, то есть, информационной части продукта, к которой также относится и API. На мой взгляд, эти критерии могут существенно пересекаться с некоторыми эвристиками, но между ними все-таки есть разница: если эвристики выбирает эксперт, то когнитивные измерения – это более или менее устоявшийся набор. Основной список измерений, предложенный автором методики Томасом Грином, можно прочитать в Wikipedia.
Некоторые компании составляют свои собственные списки критериев. Одним из наиболее интересных является список от тестировщиков Visual Studio:
- Уровень абстракции – минимальный и максимальный уровни абстракции, используемые для API, и их соответствие ожидаемым разработчиком уровням.
- Стиль обучения – необходимые знания для использования API и доступность этих знаний для разработчика.
- Рабочее окружение – дополнительные инструменты, необходимые для эффективной работы с API.
- Минимально необходимый размер кода – размер кода, необходимый для выполнения одной операции с API.
- Поэтапное оценивание – сколько кода нужно написать для того, чтобы понять, рабочий он или нет.
- Преждевременная фиксация решений – сколько решений нужно принять разработчику для написания кода определенного сценария, и каковы могут быть последствия этих решений.
- Прозрачность – насколько просто изучить, проанализировать и понять компоненты API.
- Проработка API – насколько необходимо доработать API, чтобы оно соответствовало нуждам разработчиков.
- Вязкость API – сколько усилий нужно приложить, чтобы внести изменения в API, и сколько усилий потребуется разработчику для адаптации под эти изменения.
- Согласованность – как легко можно понять принципы работы всего API, ознакомившись лишь с его частью.
- Выразительность ролей – ясны ли связи между компонентами в API, понятно ли, за что отвечают каждый метод и поля.
- Соответствие доменной области – насколько явно компоненты API соответствуют домену.
Простейший пример – это соответствие API доменной области, то есть бизнесу. В нашем сервисе ключевой сущностью является дом. У обычного многоквартирного дома бывают подъезды, а в них квартиры. Вроде бы, все просто. Но оказалось, что в Калининграде это не так: там есть дома с адресами типа ул. 8 Марта, д. 2-4, где подъездами являются дом 2 и дом 4. Такая странная (и изначально неизвестная) бизнес-ситуация ломала всю логику построения API. Например, в запросах на создание дома-подъезда пришлось добавить параметр GUID дома, а в сервисе создания общедомовых приборов учета дать возможность прикреплять их к подъездам, если подъезд – это дом.
3. Когнитивный разбор (Cognitive walkthrough)
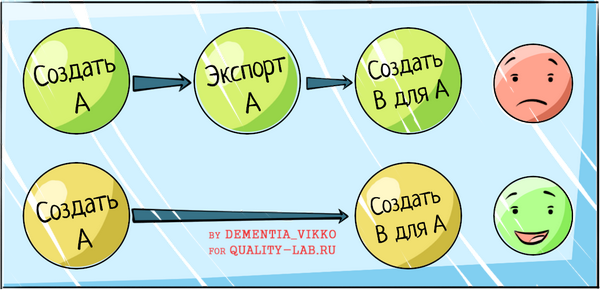
Если первые два метода основаны на «прогоне» API на соответствие какому-либо чек-листу критериев, то когнитивный разбор уже является сценарным тестированием. Суть метода в том, что эксперт по юзабилити выделяет какие-либо типовые сценарии использования API и пытается пройти по ним.
Рассмотрим пример сочетания метода когнитивного разбора и использования эвристик. При анализе сервисов оказалось, что есть проблема с последовательностью дизайна сервисов: некоторые из них при создании сущности в качестве результата возвращают идентификатор версии сущности, а другие – корневой идентификатор. При этом методы, использующие идентификатор сущности как параметр для создания других сущностей, тоже различались: где-то требовались GUID версии, а где-то – корневой GUID. Сама по себе проблема не казалась слишком серьезной до тех пор, пока мы не попробовали пройти бизнес-цепочку создания сущностей. Для создания расчета нужен корневой GUID договора, а при создании договора возвращается версионный GUID: поэтому после создания приходится делать запрос на экспорт только что созданного договора для извлечения из него корневого GUID и создания расчета. Этот экспорт является лишним шагом, «хаком» для обхода косяков системы, который ухудшает юзабилити API. В данном случае благодаря сценарному прогону мы обнаружили несоответствие и другой эвристики – «минимального объема рабочего кода».
4. Групповая экспертная оценка API (API peer review)

Эвристические оценки и когнитивный разбор – отличные методы, но в простейшем варианте они предполагают ваше непосредственное участие. Естественно, оценка выходит весьма субъективной. Для большей объективности удобно использовать групповые оценки, когда приглашается несколько людей для анализа API. Есть подробная статья от Microsoft о том, как и почему этот метод может найти дефекты юзабилити, которые редко находятся эмпирическими методами.
Основной принцип метода заключается в следующем. Выделяются четыре роли:
- эксперт по юзабилити, ответственный за организацию и модерацию процесса оценки с точки зрения юзабилити;
- человек, ответственный за конкретный кусок API, который будут оценивать;
- человек, ответственный за область, в которой находится оцениваемый кусок API (то есть, знающий контекст использования этого куска и его взаимодействие с остальными частями API);
- 3-4 человека, выполняющие некие задания, с помощью которых можно будет сделать оценку юзабилити (обычно это просто другие разработчики из компании).
На этапе планирования эксперт по юзабилити и человек, ответственный за оцениваемый кусок API, встречаются и определяют условия:
- основные вопросы, на которые нужно получить ответ в ходе оценки (например, как просто создать определенный договор используя сервис);
- примеры кода, по которым будет проходить групповая оценка;
- сотрудники, которые будут участвовать в оценке (это могут быть люди, отвечающие определенным критериям, например, имеющие опыт использования SOAP сервисов на языке Java или C#);
- место и время проведения сессия оценки.
На этапе проведения сессии оценки объясняются причины сбора и основные базовые сведения об оцениваемом API. После этого раздаются заготовленные примеры кода, и начинается обсуждение, на котором затрагиваются два основных вопроса:
- Понимаете ли вы, что делает этот код, какова его конечная цель?
- Достаточно ли логично и рационально достигается эта цель?
На основе ответов на эти вопросы эксперт по юзабилити пытается выяснить конкретные детали. Например, получив замечание о нелогичности наименования переменной, эксперт должен спросить человека, почему тот так думает и какое имя он может предложить.
Последний этап – анализ и заведение ошибок. Здесь обязательно участие человека, ответственного за всю область исследуемого API, который может помочь определить то, что в принципе является ошибкой, и подсказать, исправима она или нет.
Эмпирические методы
В противовес аналитическим методам разработаны эмпирические (или экспериментальные) – в них упор делается на исследования фактического использования продукта реальными пользователями.
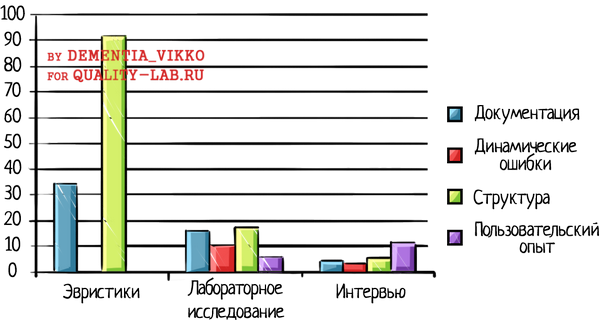
Не стоит думать, что эмпирические методы по умолчанию лучше аналитических: и те, и другие полезны для оценки юзабилити, так как они позволяют находить разные проблемы. В одном из исследований, где использовались оба подхода, было обнаружено, что эвристики в разы больше отлавливают ошибки в документации и структуре API, а эмпирические методы полезны для обнаружения субъективных проблем (пользовательский опыт) и динамических ошибок, которые можно обнаружить только при реальной работе с API (при написании кода и попытках его выполнить).
1. Мониторинг
Суть мониторинга заключается в сборе статистики об использовании вашего API. Наиболее просто это реализуемо для веб-сервисов. Например, мониторинг показывает, что какой-то API вообще не используется. Соответственно, должен быть проведен анализ для выявления причин: нет документации, или этот сервис просто не нужен? Также мониторинг позволит вам определиться с основными сценариями использования: какие обращения, к каким сервисам и в каком порядке происходят чаще всего.
Хочу обратить внимание на то, что в статистике нужно собирать данные не только об успешно завершенных обращениях к API, но и об ошибках использования. У вас накопилось очень много ошибок одного типа? Возможно, стоит пересмотреть реализацию API или документацию, ведь почему-то пользователи постоянно натыкаются на эту проблему.
Отдельно стоит выделить мониторинг объемов данных. На проекте, где я участвую, было предположение: договоры типа А должны быть более используемы, чем договоры типа Б, а значит, упор при оптимизациях сервисов делался на первый тип. Каково же было удивление, когда кто-то обнаружил, что договоров А в системе было создано 600 тысяч, а договоров типа Б – 80 миллионов. После этого открытия приоритеты по исправлению юзабилити дефектов для сервиса Б резко поменялись.
2. Анализ обращений в саппорт
Если у вас есть саппорт – это замечательно. Значит, можно провести анализ обращений, выделить из них связанные с юзабилити и определить наиболее серьезные проблемы. Я уже приводила примеры гневных отзывов на случайные кириллические символы вместо латинских: эти ошибки были обнаружены именно через саппорт.
Более того, саппорт позволяет напрямую увидеть, какие технологии используют ваши пользователи и на какие проблемы натыкаются. Недавно мы столкнулись с такой ситуацией: пользователи формировали soapAction динамически, исходя из корневой структуры запроса и просто отбрасывая слово Request. Например, importHouseRequest превращался в importHouse, и все работало. Но у нас был сервис с именем importPaymentDocumentRequest, у которого soapAction назывался не importPaymentDocument (по алгоритму пользователя), а importPaymentDocumentData. С одной стороны, пользователь применил плохой алгоритм: для этих целей обычно служит WSDL. С другой стороны, у него просто могло не быть другого выхода – и тогда этот случай надо рассмотреть подробнее: почему во всех сервисах у нас есть определенная закономерность, а в этом – нет?
3. Опросы и анкетирование
У вас может не быть саппорта, или же он может не давать достаточно информации для исследования. В таком случае можно запустить процедуру анкетирования конечных пользователей. Приводить список конкретных вопросов не имеет смысла, так как они индивидуальны для каждого случая. Но хорошим началом станут базовые вопросы: «Что вам нравится при использовании сервиса? Что не нравится? Что бы вы хотели изменить и как?»
4. «Лабораторное» тестирование юзабилити
Это самый затратный и дорогостоящий метод оценки юзабилити. Идея заключается в том, чтобы найти людей, максимально подходящих под профиль ваших пользователей, дать им определенные задания, следить за их выполнением и сделать определенные выводы на основе анализа выполнения.
Каждая компания делает это по-своему. Кто-то проводит удаленные сессии с разработчиками, где им выдаются задания уровня «используйте такое-то API для такой-то задачи», а затем проводится интервью. Другие компании приглашают разработчиков к себе и проводят аналогичные сессии. Хорошим тоном в этом случае будет предоставление возможности принести свои ноутбуки и пользоваться своими средами разработки: во-первых, это больше соответствует условиям использования ваших API в реальной среде, а во-вторых, уменьшает влияние фактора незнакомого окружения.
С другой стороны, есть примеры более экзотических сессий. Разработчика заводят в комнату с зеркалом, которое прозрачно с одной стороны (да-да, как в фильмах про полицию!). За зеркалом сидит эксперт по юзабилити, который, во-первых, наблюдает за действиями разработчика через стекло, а во-вторых, видит на мониторе все происходящее на компьютере разработчика. Разработчик может воспользоваться системой связи с экспертом при возникновении вопросов, но эксперт отвечает только в тупиковых случаях. На мой взгляд, это уже чрезмерно «лабораторный» тест, но иногда используют и его.
Приведу примеры заданий, выдаваемых разработчикам для оценки работы с API:
- выполнение определенного задания без IDE, в блокноте (обычно используется для анализа того, как пользователь сам бы реализовал API);
- практические задания по использованию API (напишите код для достижения какой-либо цели, например, для загрузки файла с помощью сервиса);
- анализ предоставленного кода с точки зрения понятности и читаемости API (примеры кода можно давать в виде распечаток – тогда задание становится более сложным);
- анализ и дебаг кода, вызывающий ошибки (позволяет определить то, как пользователь будет обходить и исправлять ситуации в том случае, когда ваш сервис вернет ошибки).
Практически все такие исследования содержат фазу интервью, где задаются вопросы такого плана:
- Назовите три самые большие проблемы, на которые вы наткнулись при выполнении заданий, и выбранные вами способы их решения (документация, саппорт, stackoverflow, помощь друга).
- Дайте примерную оценку времени, которое вы потратили на поиск вспомогательной информации вне официальной документации API (0% – «я использовал только официальную документацию», 100% – «я использовал официальную документацию только чтобы получить ключ разработчика»).
- Наткнулись ли вы на неожиданные ошибки? Если да, то помогли ли вам сами сообщения об ошибке?
- Назовите как минимум три способа улучшения официальной документации.
- Назовите как минимум три способа улучшения дизайна самого API.
Персоны
Персоны – это особая техника, которая применима как в аналитических, так и в эмпирических методах. Суть заключается в выделении специфических характеристик конечных пользователей (в случае API – разработчиков). Нужно поработать и над «очеловечиванием» этих характеристик: придумать имя, подобрать фото, определить, что они «любят» и чего «боятся» в работе. Определив основные «персоны», тестировщик юзабилити может примерять их к себе в ходе применения аналитических методов или использовать при наборе людей для лабораторного тестирования.
Простейшие персоны разработчиков:

- Методичный разработчик. Не доверяет всем API, использует техники defensive programming. К решению задач подходит от общего к частному. Коммитит в ядро Линукс, пишет на C++, C, а то и на ассемблере.
- Разработчик-прагматик. Обычный разработчик, может подходить к задаче как от общего к частному, так и наоборот. Пишет десктопные или мобильные приложения. Основные языки – Java или C#.
- Разработчик-авантюрист. Решает задачи от частного к общему, очень доверчив к API. Просто делает так, чтобы все более или менее работало. Использует языки типа Javascript.
Хочу заметить, что указанный языковой «расизм» – не моя придумка, эта схема почерпнута у Microsoft. Это всего лишь пример, который может пригодиться вам при определении персон для своего проекта.
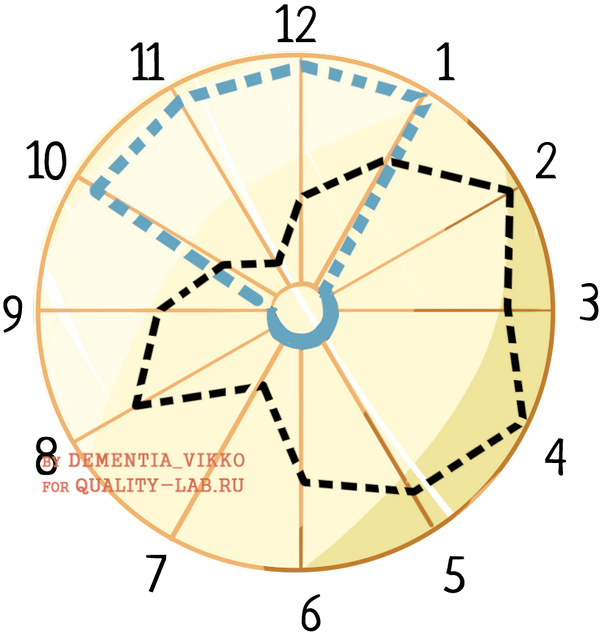
Интересной идеей является сочетание персон и когнитивных измерений. Можно сделать график, в котором оси, выходящие из центра, – значения по измерению, а секторы будут представлять каждое из измерений, где нумерация идет от 1 (уровень абстракции) до 12 (соответствие доменной области).
На этот график можно нанести реальную текущую оценку вашего API по измерениям (черная линия) и оценку по ожиданиям определенной персоны (синяя линия). На получившемся графике можно сравнить, насколько ожидания персон совпадают с реальным состоянием API. Персона с графика – это разработчик, который мечтает об API с высоким уровнем согласованности (10), но при этом хочет написать как можно меньше кода (4). Как видим, текущее состояние API слабо удовлетворяет его потребности по этим критериям.
Вывод
Читатель, знакомый с техниками юзабилити-тестирования, применяемыми для GUI приложений, может сказать: «Да ведь это все то же самое!» И он будет прав, ведь ничего сверхъестественного в юзабилити API нет. Мы ведем речь об APPLICATION PROGRAMMING interface, но, к сожалению, программы еще не научились самостоятельно находить API других программ и внедрять их в себя: для этого пока еще нужна «прослойка» в виде человека-разработчика. Поэтому когнитивные особенности, используемые для GUI юзабилити, почти полностью применимы и для API. Основное отличие заключается в том, какие конкретно задачи нужно ставить при тестировании, и какие эвристики будут использоваться.
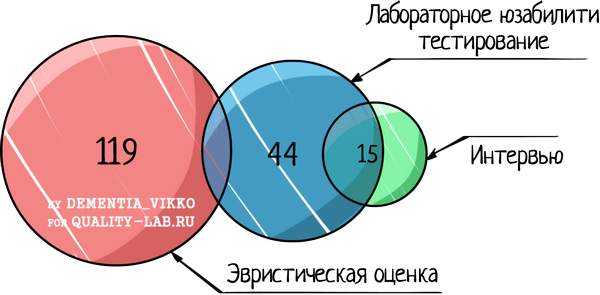
На вопрос же, какой способ оценки применять на проекте, можно дать простой ответ: «Все!». Согласно исследованию, в котором использовали эвристики, лабораторное тестирование и интервью, новые дефекты юзабилити были обнаружены с помощью всех трех техник.
И все-таки, если у вас ограничены время и ресурсы, я рекомендую начать с самых незатратных техник. Это будут эвристики, когнитивные измерения и разбор (все три можно сочетать в одной сессии тестирования), а также анализ инцидентов от саппорта. И помните: даже самые простые техники могут открыть массу идей для улучшения API вашего продукта.
Кому-то может показаться, что тестирование юзабилити API – это дело далекого будущего, и сейчас никто не будет тратить на это время. Но ведь разработчики уже давно при написании кода используют определенные правила, делающие код удобным и читаемым. Эта традиция возникла не на пустом месте: она была продиктована нуждами отрасли и бизнеса. Если мы думаем о качестве кода «внутри», то и качество кода, выставляемого «наружу» (API), не должно оставаться без внимания.











