Последний и самый короткий месяц зимы выдался необычайно насыщенным новаторскими подходами и свежими решениями в автотестировании. Сегодняшнее повествование целиком и полностью посвящено автоматизации, и для этого есть множество причин:
- автоматизация — это высшее благо при проведении регрессионного тестирования!
- автоматизация помогает исключить человеческий фактор, а значит минимизировать ошибки!
- все, что может быть автоматизировано, должно быть автоматизировано!
А теперь с удовольствием и гордостью представляем на ваш суд каждое достижение, успешно реализованное нами в феврале.
Инфраструктура для работы вроде как бы есть, но ее как бы нет? Мы всё исправим!
Несколько месяцев назад на проекте по тестированию страхового ПО была внедрена долгожданная автоматизация. Однако, как это обычно и бывает, довольно скоро мы, увы, столкнулись с некоторыми проблемами:
- во-первых, невозможно было настроить запуски;
- во-вторых, автотесты запускались локально (локально, Карл!) без разделения по наборам, т. е. все запускалось последовательно на одном терминале и занимало уйму времени;
- в-третьих, полный отчет о проведенном автоматизированном тестировании приложения нигде и никак не фиксировался;
- и, в-четвёртых, человеческий фактор, конечно же, тоже никто не отменял: сотрудники элементарно могли ошибочно запустить не тот набор.
Как мы работали над этими проблемами?
Наш автоматизатор написал центральный сервер для управления агентами тестирования и потоком задач для них. Под агентами мы понимаем небольшие приложения-клиенты, которые получают информацию по запуску с ЦС и отправляют результаты выполнения задачи.

Говоря другими словами, была создана такая рабочая инфраструктура, благодаря которой появилась простота и ясность при выполнении задач.
Что нам это дало?
- наше решение не требует какой-либо повышенной квалификации от тестировщика по настройке и запуску среды для тестирования. Всё запускается одной кнопкой, что полностью исключает вероятность ошибки на этом этапе;
- никаких больше локальных прогонов. Вся информация о результатах автотестов аккумулирована в одном месте — в TestRails на стороне заказчика;
- одновременно была решена проблема с параллельным запуском тестов;
- мы существенно сэкономили время на запусках — полторы минуты против 7,5 часов. Как говорится, почувствуйте разницу.

Инфраструктура для работы с автотестами попросту отсутствует? Так мы поднимем!
На проекте по тестированию ветеринарного сервиса и записи питомцев в клиники мы настроили всю инфраструктуру автоматизации с нуля. Сделано это было для того, чтобы тесты запускались сразу после обновления dev-stage стенда или же при необходимости вручную. И сделано хорошо — настройка дает нам возможность просматривать отчеты по автотестам в виде подробного и красивого Allure Report и запускать автотесты в различных браузерах, используя linux-окружение без GUI.
Осветим поподробнее, как мы «скрестили» несколько инструментов, и что нам это дало.
Итак, Docker.
Всё окружение для работы браузера и GUI автотестов находится внутри Docker — контейнеров. Docker значительно упростил запуск тестов, повысил стабильность и позволил запускать тесты в параллель в несколько потоков, что значительно сократило время общего прогона (с 3-х до 1-го часа).

Selenoid
Ни для кого не секрет, что нужно настроить окружение для автотестов и браузера, чтобы эти автотесты где-то запускались. Можно было бы создать ВМ (или физическую машину) на Windows, где запустить Selenium Grid Node для нужного браузера, например, для Chrome. Но Selenium Grid — очень нестабильная штука, и нужно тщательно следить за процессом, перезапускать, перезагружать (кто работал с ней — понимают). Либо создать ВМ на linux (установить там рабочий стол, например xvfb и также запустить Selenium Grid. А что делать, если браузер обновится? Придётся менять версию селениум драйвера, менять настройки Grid и прочее…
Вместо этих непродуктивных вариантов есть замечательный Selenoid. Браузер с xvfb запускается в Docker-контейнере, и ничего не зависает. Новые версии браузеров добавляются прямо на лету. И все это работает на любом Linux-сервере без рабочего стола. Есть и ещё одна немаловажная деталь: Selenoid позволит запускать тесты параллельно. Тогда как без него нам нужно было бы ещё несколько ВМ поднимать, которые работают ВСЕГДА, а не только когда запущены автотесты.
Allure
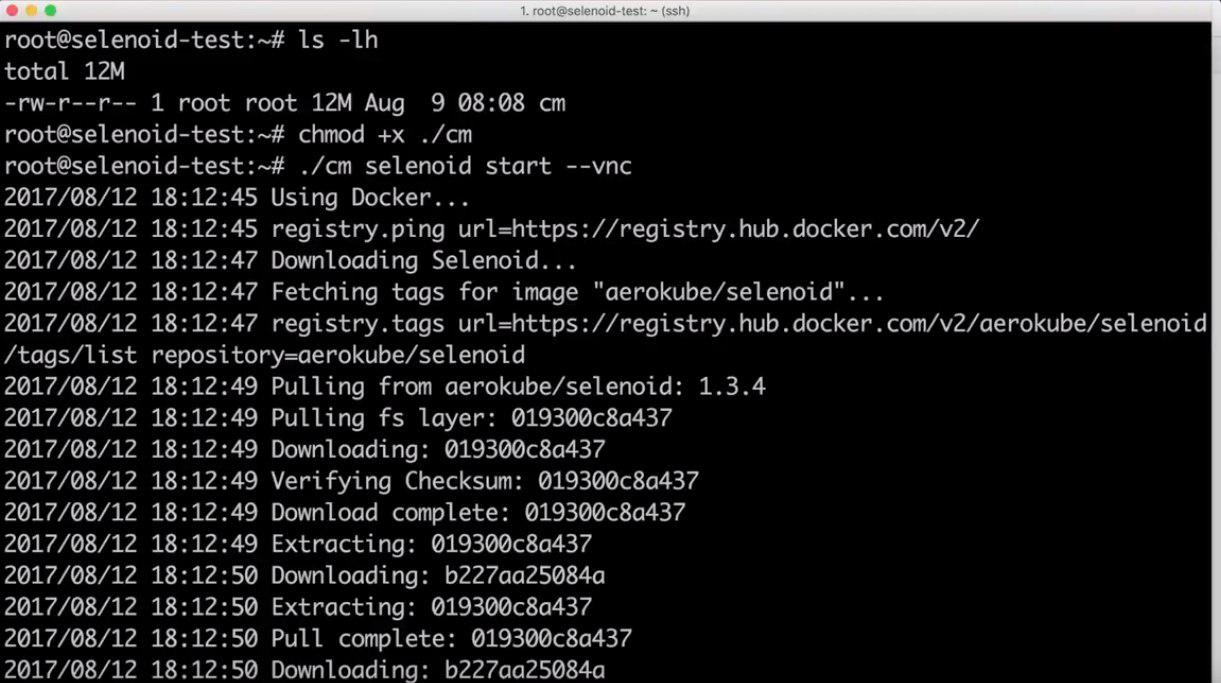
Отчёты по результатам наших автотестов мы решили доверить исключительно Allure. Здесь автотесты разделены на категории, которые в отчёте отображены в виде папок. Внутри отчета конкретного теста можно увидеть описание шагов.
При возникновении ошибки и падении автотеста, мы видим конкретный шаг и скриншот приложения в этот момент. Если это ошибка в приложении, то она легко локализуема.

Чего мы добились?
- у нас появились видео, которые пригодились для отладки тестов;
- в любой момент времени мы можем контролировать автотесты через Selenoid-UI;
- отчётность по результатам прогонов не только понятна и информативна, но ещё и красива. Все методы видны в отчёте, и можно сразу отследить, где и почему упал автотест.
Инфраструктура у заказчика есть, но нужно встроить автоматизацию регрессов?
На проекте по тестированию web-приложения для регистрации компаний в Сингапуре может проходить по несколько релизов в день. А релизы могут быть как крупные, так и мелкие, что накладывает свои ограничения на возможности проведения регрессов. Наши тестировщики попросту не успевали проверять всё вручную! Заказчик, естественно, желал ускорить тестовый цикл, но считал, что это невозможно. Когда мы начали анализ автоматизации на проекте, то столкнулись со следующими проблемами:
- неоднородная инфраструктура: применяются неклассические решения и инструменты, которые сильно ограничены в функционале (в итоге используется по несколько однотипных инструментов под разные задачи);
- ограничение по серверным ресурсам и стендам для тестирования;
- объективная сложность при встраивании потенциальной автоматизации в уже существующую инфраструктуру. На stackoverflow вообще утверждалось, что это невозможно.
Мы собрались с духом, засучили рукава, побрейнштормили и смогли найти возможности, при которых автоматизации «быть». А далее реализовали следующую схему:
- коммит с изменением кода продукта инициирует выполнение скрипта в Pipeline, который собирает образ продукта;
- прежде чем будет поднят сервер на AWS со сборкой, проводятся unit-тесты;
- при успешном прохождении unit-тестов, собирается готовый для тестирования продукт и скрипт возвращает необходимые для последующих действий параметры;
- далее в дело вступает написанный нами скрипт, который собирает всю необходимую информацию, и на её основе запускает в CI автотесты подходящей конфигурации;
- будет ли инициирован автоматический деплой на продакшн-стенд или нет, зависит от успешности автотестов;
- итоги автоматически сообщаются в slack, а дополнительная наглядность демонстрируется в отчетах Allure и видео прогонах, которые также доступны в этих отчетах.
Что в сухом остатке? Безболезненное решение проблем проведения регрессов при любом релизе — от мала до велика — без какого-либо вмешательства в существующую инфраструктуру проекта.
Мы минимально отошли от инфраструктуры проекта, тем самым сохраняя однородность инструментов, стабильность инфраструктуры и исключая человеческий фактор. Заметим, что защита информации — очень важный для нас момент в работе на любом из проектов. И, конечно же, теперь наши автотесты стабильно ловят наведенные дефекты, тем самым минимизируя риски при столь частых релизах. А затраты при этом минимальны, потому что, внедряя любое решение, мы стараемся учитывать оптимальность и финансовых, и человеческих ресурсов.
Мораль
Даже если на написано, что чего-то сделать нельзя, это вовсе не означает незыблемости таких категорических утверждений. Наши специалисты читают не только форумы, но и документацию, и способны отыскать способы решить задачи любой сложности.
Внедряйте ваши автотесты умело, и да пребудет с вами сила! Ну или мы прибудем к вам и научим делать это хорошо!
ЕСЛИ У ВАС ПОЯВИЛИСЬ ВОПРОСЫ (а мы надеемся, что они появились) — задавайте их через форму “Получить совет”, а также ждем ваши комментарии к этой статье.










