Срыв сроков выпуска ПО – часто возникающая проблема, от которой не застрахован ни один проект. Причины такого явления кроются в разнообразных непредвиденных ситуациях, связанных с деятельностью заказчиков, разработчиков или тестировщиков. К счастью, эту проблему, как и большинство других, можно предотвратить.
В данной статье я рассмотрю вопрос выделения достаточного количества времени на проведения тестов. Практика показывает, что именно на этом шаге создания продукта время зачастую экономится («там всего-то протестировать на полчасика – и все»). Для того, чтобы понять, почему нам важно выделить достаточно времени для проведения тестов, подробно рассмотрим, какие именно факторы могут привести к срыву сроков.

Что такое «достаточность времени» и как ее рассчитать?
1. Определение
Итак, что подразумевается под «достаточностью времени», и чем «достаточное время» отличается от «номинального»? «Номинальное время» затрачивается на работу в идеальных условиях (без непредвиденных ситуаций). Но бывает ли так на практике?
Например, для установки компьютерной игры или программы в прилагаемой спецификации ПО приводятся номинальные и рекомендуемые (достаточные) характеристики ПК. Не следует ожидать от продукта высокой производительности, если технические параметры компьютера будут близки к номинальным требованиям. Именно поэтому рекомендуемые (достаточные) параметры для установки ПО всегда превышают номинальные.
В нашем же случае «достаточное время» – это время, которого гарантированно хватает для завершения поставленных задач даже в случае возникновения непредвиденных проблем. В этой статье я приведу реальные примеры из моей практики работы на двух проектах. Один из них обозначу «Отелем», а другой – «Утилитой».
2. Расчет
Для определения потребности времени и минимизации его нехватки предлагаю воспользоваться диаграммой Исикавы. Она проста и наглядна, с ее помощью можно визуально облегчить разбор причин, которые приводят к недостатку времени на тестирование. Сама диаграмма применяется для определения причин возникновения проблем, но в нашем случае она поможет просто и понятно систематизировать все потенциальные причины, приводящие к срыву сроков, а также обозначить их компенсаторы.
Для простоты и наглядности используемая мной для демонстрации диаграмма будет весьма краткой. Для вашей задачи она «ощетинится» и создаст хорошую базу для расчетов, как на иллюстрации ниже.

По клику на картинку откроется полная версия.
Итак, зададим план действий с использованием данной диаграммы:
- Рисуем костяк диаграммы.
- С помощью мозгового штурма находим причины, которые приводят к дефициту времени.
- Группируем причины по факторам и отображаем на диаграмме.
- Вновь проводим мозговой штурм, уже имея перед глазами диаграмму, которая помогает мыслить в заданном направлении (возможно, идей в этот раз уже не будет так много, как при первом штурме, но зато они приобретут некую упорядоченность).
- Учитывая найденные проблемы, находим способы их нивелировать. Добавляем эти решения в диаграмму.
- Завершаем работу над отрисовкой диаграммы.
- Проводим оценку временных рисков с учетом найденных проблем (то есть, проставляем время, которое может отнять та или иная проблема).
- Вычисляем достаточное время, которое учитывает все возможные риски на проекте.
Разберем эту последовательность на примере. Нарисуем костяк диаграммы:

Похоже на рыбу? Собственно, «рыбной» ее и называют. «Позвоночник» – это и есть номинальное время. Оно прямое, ничто ему не мешает в идеальных условиях. Далее вписываем время, которого будет достаточно для проведения тестирования без учета рисков. Например, оценим его в 640 человеко-часов в месяц (условно, тестировать продукт мы будем на протяжении месяца).

После создания основы диаграммы мы проведем мозговой штурм и проанализируем проблемы.
Виды проблем
Существует множество проблем, которые приводят к срыву сроков. Одни из них возникают крайне редко, другие же встречаются едва ли не в каждом проекте. Исходя из личного опыта, я разделил все проблемы на 4 вида:
- технические;
- социальные;
- ментальные;
- форс-мажорные.
Технические проблемы
Итак, первой «костью» нашей диаграммы станет технический фактор:

Наиболее характерными техническими проблемами являются «падение» сервера или неожиданное отключение интернета/электричества у тестировщика (это не так критично в том случае, когда тестировщиков много). Кто виноват и что предпринять? Поиск виновного не поможет делу. Если «упал» сервер, на котором «висит» проект, то работа останавливается полностью. Насколько долго? Если сервер контролируется заказчиком/разработчиком, то все не так страшно. Но вот если он принадлежит стороннему хостеру…
Пример из практики: «Утилита», проблема с сервером.
Первоначально на проекте хватало имеющихся мощностей и тестовых стендов, но от заказчика поступила специфическая задача, потребовавшая обращения к стороннему провайдеру с целью получения необходимых стендов. Был найден провайдер-хостер, передана необходимая для конфигурации окружения информация, обозначены сроки выполнения. Внезапно хостер стал «кормить завтраками», нарушая предварительные договоренности.
К счастью, заказчик был лоялен, и мы смогли изменить сроки, но при получении доступов к стендам выявился ряд проблем, осложнивших тестирование:
- пропадал доступ к серверам хостера (из-за работ, которые он проводил);
- при работе с сервером возникали ошибки;
- сервер хостера «падал», и на устранение причин аварии уходил день, а то и два.
Время шло, сроки поджимали, работа стопорилась… Лихорадочно велись поиски других вариантов, НО ВРЕМЯ БЫЛО УПУЩЕНО! В итоге заказчик предпочел отказаться от наших услуг без развернутого объяснения причин. И это понятно: в конечном счете, именно мы как исполнители работ брали на себя возможные риски и должны были учесть их при подготовке и выполнении несложной задачи по организации стендов для проведения тестирования.
Нужно помнить, что технические проблемы в сфере IT – не редкость, они возникают в том или ином масштабе. И уж если мы подстраховываемся в бытовых вопросах (например, откладывая средства на непредвиденные расходы), то риск вероятного отказа оборудования должен быть учтен обязательно. Проблемы с сервером могут возникнуть при тестировании как сайта, так и софта (если ПО во время своей работы взаимодействует с сервером). Следовательно, нужно заранее предусмотреть запас времени с учетом простоя, в течение которого сисадмин будет восстанавливать работоспособность сервера. Вопрос с поломками ПК самого тестировщика я рассмотрю чуть позже.
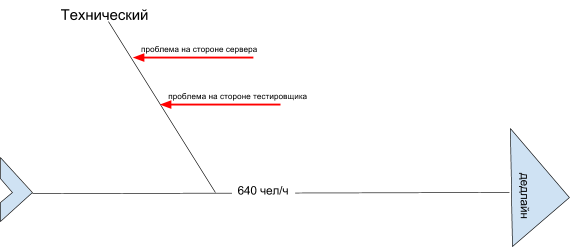
На нашей диаграмме Исикавы фактор «Технический» содержит риски:
- проблема на стороне сервера;
- проблема на стороне тестировщика.
По клику на картинку откроется полная версия.
Как рассчитать необходимое время и учесть опыт на будущее
- Учитываем информацию о работе сервера, то есть его uptime (например, 98%).
- Выделяем время, необходимое на восстановление работоспособности сервера. Исходя из моего опыта, максимальное время – 5 часов (с учетом попытки восстановить работу, установки резервного сервера на новую машину, переконфигурирования, загрузки сохраненной копии).
- Учитываем время (исходя из личного опыта), которое требуется для восстановления работоспособности тестировщика (если он работает удаленно) – от 1 до 4 часов.
- Определяем способы, которые помогут частично или полностью нивелировать действие возникших проблем, выделяем время и для их реализации.
NB! Здесь и далее числовые значения я буду назначать условно, так как цель статьи – не мастер-класс по учету рисков времени, а рассмотрение проблемы как таковой.
Итак, конкретизируем список:
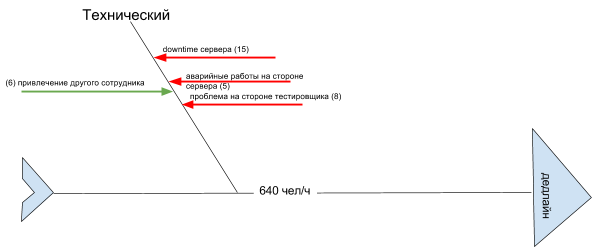
- downtime (простой) сервера на проекте согласно собранным среднестатическим данным – 15 часов в сутки (предположим, что весь простой приходится на рабочее время);
- аварийное возобновление работы сервера – максимум 5 часов;
- возобновление работы тестировщика с учетом среднестатического количества работников, с которыми это случается (2 чел.), – 2 * 4 = 8 часов в месяц;
- возможность привлечения (в случае необходимости) работников из других проектов – предположительно 6 человеко-часов.
По клику на картинку откроется полная версия.
Диаграмма показывает степень рисков и возможность их компенсации. В соответствии с законом Мерфи нужно готовиться к худшему:
- все негативные случаи могут иметь место;
- компенсировать их не получится.
Красным цветом на диаграмме мы обозначаем риски потери времени, а зеленым – возможную компенсацию:

По клику на картинку откроется полная версия.
Социальные проблемы
Фактор социальных проблем проявляется достаточно часто, но при этом почему-то нередко игнорируется при планировании времени работы. Проблемы эти сложны для расчета компенсации, но предусматривать их наличие нужно в любом случае: ведь, к примеру, тестировщик может заболеть, уйти в отпуск, уволиться или даже умереть.
Конечно, опытный ПМ уже наперед предусматривает варианты замены людей в том или ином случае. Но, например, поручив Пете работу его коллеги Васи, неожиданно выбывшего из проекта, он вряд ли сможет заставить Петю работать по 16 часов в день. Даже если такое и удастся – скорее всего, Петю очень скоро придется заменять другим тестировщиком (если, конечно, кто-то выразит желание выполнять обязанности троих человек и работать 24 часа в сутки). Следовательно, нужно учитывать, что даже при замене людей тестирование замедляется.
Можно, конечно, попросить кого-то перенести законный отпуск (хотя, дело это довольно трудное, особенно если речь идет о семейных сотрудниках). Но если сотрудник заболел или уволился, придется жертвовать временем, отведенным для тестирования – ввод другого сотрудника в проект сразу не поможет стабилизировать ситуацию, так как ему нужно войти в курс дела. И если смерть и увольнение – относительно редкие случаи, то отпуск, а особенно болезнь сотрудника или семейные обстоятельства, – обычные явления.
Примеры из практики: «Отель», увольнение сотрудников.
В течение нескольких месяцев из проекта по ряду причин ушли ПМ (со стороны заказчика), ведущий тестировщик и команда разработки (третья сторона).
Система отслеживания ошибок Jira, которая также использовалась в качестве системы управления проектом, была развернута на сервере команды разработки. После ухода этой команды из проекта нам довелось столкнуться с целым рядом проблем. Мы остались без заведенных багов и созданных задач. В спешном порядке пришлось подбирать удобные для использования системы багтрекинга и ведения документации. Параллельно с этим мне приходилось оформлять свеже-найденные баги в багтрекере нашей компании, а после установки нужной системы у заказчика – переносить все уже заведенные баг-репорты к нему. Кроме того, я заводил новые баг-репорты и восстанавливал «утраченные», а также проводил регресс исправленных.
В условиях постоянного цейтнота мы все-таки уложились в сроки. Из этого эпизода были сделаны выводы, и сейчас подобные ситуации станут лишь досадной неприятностью, но существенных проблем не принесут.
Пример из практики: «Утилита», болезни, отпуск, уход из проекта.
Сначала интересный проект развивался неплохо, работа шла слаженно… В июле один из тестировщиков ушел из проекта, команда сократилась до 3 сотрудников (включая ТМ). В конце июля – начале августа я сначала заболел на 2 недели, а затем ушел в двухнедельный отпуск. На следующий день после моего возвращения ТМ ушел в отпуск, а затем заболел (в сумме — месяц). Мне пришлось заменять его, но это получилось не слишком удачно.
Итого: 8 недель работы команды, теоретически состоящей из трех человек, а практически – из двух. Реальная история. При этом заказчика не должно заботить, кто и чем болеет или на сколько уходит в отпуск. Обязанности по соблюдению заявленных сроков лежат на нас.
Пригодилось то, что наш ТМ взял хороший запас по времени для выполнения задач, причем использовал сложные насыщенные таблицы расчета рисков и времени. Тут уж никуда не денешься: либо мы грамотно учитываем риски, либо овертаймим, чтобы как-то не упустить дедлайн. Расчет всегда полезен: если мы запросим неоправданно много времени, заказчик может найти кого-то «побыстрее», если слишком мало – мы с большой вероятностью накажем сами себя. Из опыта других фирм я наслышан об иных проблемах. Например, сотрудник мог просто без предупреждения уйти на лучшую работу, не волнуясь за трудовую книжку, или сотрудника могли с треском уволить по разным причинам.
Практически все упомянутые случаи (кроме отпуска), предугадать невозможно, но все они ведут к нарушению обычного режима работы. Поэтому их необходимо предусмотреть (с учетом собственного или чужого опыта), и выделить определенное количество времени для искоренения негативных последствий.
Как рассчитать необходимое время и учесть опыт на будущее
Для учета таких рисков берем личные среднестатические данные по следующим вопросам:
- сколько времени затрачивается на ввод нового сотрудника в проект (например, 6 часов);
- сколько времени проводит сотрудник на больничном (например, 4 дня);
- сколько сотрудников уходит на больничный (6% от общего количества в зимнее время);
- сколько человек уходит в отпуск (чаще всего в летний период);
- среднее количество дней отпуска (например, от 7 до 14 календарных дней);
- сколько часов тратится на помощь коллегам из другого проекта, на котором складывается более критичная ситуация (например, 2-4 рабочих дня).
Если мы чего-то не учтем – кому-то придется работать по ночам, а у кого-то будет «гореть под ногами земля».
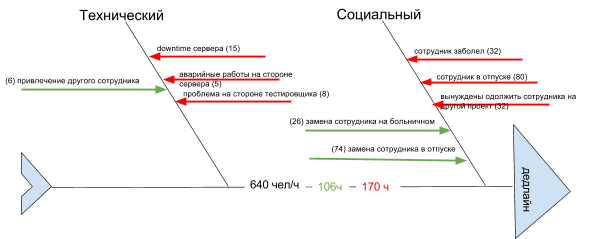
Рассчитаем риски, связанные с заболеванием. По статистике в команде из 4-х человек за месяц заболевает 1 человек (4 * 6% округляем в большую сторону), его нужно заменить, получаем:
- (4 * 8) – количество рабочих часов, которое будет отсутствовать сотрудник на больничном;
- (4 * 8 — 6) – количество рабочих часов, которое новый привлеченный из другого проекта сотрудник сможет отработать (учитываем, что он потратит 6 часов на ознакомление, вход в курс дела, получение доступов и т. п.);
- итого «- 6 часов» – потеря времени из-за болезни.
Теперь рассмотрим случай отпуска сотрудника. Допустим, в среднем по календарю отпуск длится 2 недели. Замена отпускника другим работником повлечет за собой те же 6 часов затрат. Учтем также, что в это же время нам придется помочь коллегам на другом проекте, потратив 4 рабочих дня. Суммарно по всем рискам выходит 6 часов + 6 часов + 32 часа = 48 часов.
В итоге получаем следующее состояние диаграммы:
По клику на картинку откроется полная версия.
Я не рассматриваю такие критические случаи, как увольнение или смерть сотрудника, чтобы не перегружать статью сложными подсчетами (приходится искать нового сотрудника в проект на постоянной основе). Учитывать такого рода случайности или нет – зависит от вас, но в правильном расчете мы должны учитывать все более или менее реалистичные инциденты.
На диаграмме видно, что у нас набежало 170 «красных» часов. И не обольщайтесь «зеленой» суммой: она показывает, насколько мы можем компенсировать риски по времени в идеальном случае. В реальной практике компенсаций может и не быть, поэтому мы должны рассчитывать на худший вариант и быть готовыми к нему.
Ментальные проблемы
В этом разделе я выделю две главные проблемы, которые возникают при работе тестировщиков и/или ТМ:
- непонимание или неправильное понимание ТЗ;
- переоценка своих сил.
Пример из практики: «Отель», ТЗ и переоценка своих сил.
Была поставлена задача проверить новый функционал – матрицу расчета ценообразования с учетом сезонов, скидок и выплаты процентов по двум видам договоров. В наличии было ТЗ, установленные сроки и стенд. Уже в начале работ стали очевидны проблемы:
- ТЗ для тестировщиков было написано непонятно;
- ТЗ для разработчика лежало где-то на Дропбоксе, в какой-то папке с запутанным вложением (автора уже не было в команде, другие сотрудники слабо в этом разбирались, и вопрос «а как тогда вы работали?» завис в воздухе);
- сам реализатор задачи куда-то пропал, внятных сведений о нем и о ТЗ получить не удалось.
Все мы знаем, что задачи должны быть предельно внятно описаны и грамотно поставлены, и тогда тестировщику останется просто сделать свою работу. В данном случае картина была иная, но заказчику был нужен результат, а не разбор полетов. Пришлось, применив метод обратной инженерии, выяснять, как что работает, и какие формулы задействованы. В итоге мы разобрались в задаче и составили в Гугл-Таблицах калькулятор для расчета конечной цены. Правда, времени это заняло очень много.
Второй случай относился не столько к тестированию, сколько к составлению документации. По обоюдной договоренности между заказчиком и нами была поставлена задача привести ТЗ в порядок, чтобы самим иметь под рукой детально описанные требования, которые можно показать и другим в случае необходимости. Я озвучил заказчику срок выполнения работ – 3 недели, которые в итоге растянулись на 6 недель. Я просчитался на 100%, переоценив свои силы и не имея опыта в подобных расчетах. К счастью, это не имело последствий, так как на проекте были задержки со стороны разработки. Меня никто не трогал, и я спокойно завершил свою задачу.
Да, мы не всегда можем объективно оценить свои силы и определить реальные сроки. Ошибка в большую сторону – это еще не беда, но при ошибке в меньшую сторону кому-то придется наверстывать упущенные дни. Большой удачей будет, если наверстать их получится. Ну а если нет?
Как рассчитать необходимое время и учесть опыт на будущее
Конкретные расчеты по этому виду рисков я не буду вписывать в диаграмму, так как не рассматривал типичные случае. Это не означает, что таковых не бывает, – просто по ним трудно предусмотреть затраченное время. Каждый инцидент по-своему уникален и может «украсть» разное время: от 0,5 часа до 7 часов работы (последняя цифра взята из реального случая, когда через 7 часов работы ТМ понял, что выдал сотрудникам для теста не ту версию продукта).
При невозможно проведения точного расчета я советую увеличить номинальное время на 10-15%. Конечно, не факт, что введенной прибавки хватит, но, как показывает практика, такой буфер является оптимальным: это все-таки лучше, чем не учитывать риски вообще (диаграмму смотрите в следующем подразделе).
Форс-мажоры
Сюда я отношу остальные проблемы, которые при рассмотрении всех известных рисков не учитываются просто потому, что их невозможно представить.
Пример из практики: «Отель», излишний учет.
На проекте «Отель» у меня была таблица, где учитывалось среднее количество багов, времени, потраченного на их обнаружение и репорт, и времени на внесение изменений в чек-листы. Благодаря этой таблице можно было предусмотреть, сколько времени может занять тестирование того или иного функционала, нового или уже внедренного, но обновленного. Все было бы хорошо, но выдавались дни, когда заводилось по 25 (плюс-минус 2-3) репортов. Исходя из ряда обстоятельств, нужно было регрессить все ошибки, не забывая о проверке нового функционала и прочих не менее приоритетных задачах. Сроки сдвигались, так как физически сложно было обработать весь этот массив в оговоренное время.
Сроки есть сроки, и если они не соблюдаются, нужно подключать других работников. Проект должен быть сдан вовремя. Следовательно, нужно вновь учитывать время по аналогии с ситуацией заболевания/увольнения тестировщика. Слишком много учета? Но вряд ли вы предпочтете «бешеный темп работы перед дедлайном».
Как рассчитать необходимое время и учесть опыт на будущее
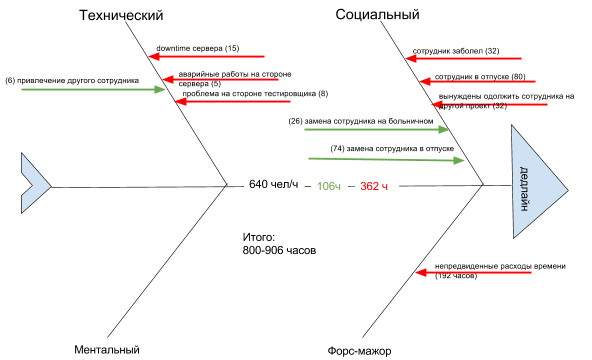
По сложившейся практике для учета непредвиденных случаев рекомендуется закладывать от 10-15% до 30% первоначально запланированного времени. В итоге наша диаграмма будет выглядеть так:
По клику на картинку откроется полная версия.
Выглядит сложно? Да, но опыт вскоре позволит вам определять нужный запас времени почти на интуитивном уровне (хотя, конечно, отказываться от расчетов не следует). Вы скажете, что «другие не занимаются этой «ерундой» и у них «все ок»? Я могу привести в пример совсем другие случаи, когда игнорирование этой «ерунды» приводило к печальным последствиям.
В соответствии с получившейся диаграммой есть риск нехватки 362 рабочих часов. Даже если удастся компенсировать риски, нам все равно нужно дополнительно учесть 256 часов. Полученный буфер времени (256-362 часа в нашем примере) мы добавим к общей длительности проекта, а не к его частям, как и советует Лоуренс Лич в книге «Вовремя и в рамках бюджета. Управление проектами по методу критической цепи», так как:
- нам в любом случае нужно дать заказчику общий срок завершения задачи (его не интересует, какая часть за какой срок будет завершена);
- тяжело просчитать, сколько именно времени нужно добавить к той или иной части проекта. Диаграмма Ганта (а именно она применяется в таких случаях) почти всегда подводит при планировании (Jeff Sutherland, «Scrum. The art of doing twice the work in half the time», Crown Business, New York), а потому достаточно будет просто учесть буфер, а не распределять его между частями проекта.
Заключение
Подведем итоги. Возможно, ранее нам казалось, что любые возникающие при тестировании проблемы можно решить за два-три дня, лишь слегка превысив заявленные сроки. Теперь, прочитав статью и взглянув на диаграмму, вы видите, что планируемый дефицит времени достигает значительных величин (в нашем случае – более 56%) даже при учете только самых типичных случаев.
Эта цифра подтверждается неоднократными наблюдениями: во многих случаях для качественного тестирования проекта приходится добавлять к планируемому времени 50-100% – смотрите «Управление рисками в высокотехнологичных проектах: состояние и подходы управления» (М.Д. Годлевский, А.А. Поляков). Но даже и эти проценты, как я уже говорил, – всего лишь средние величины, потому достаточное время необходимо рассчитывать для каждого конкретного проекта.
Да, у нас может быть определенное количество времени на компенсации (в нашем примере – 106 часов), но его использование не всегда возможно. Если мы подготовимся к дефициту времени без учета компенсации, то наличие компенсации в том или ином объеме станет для нас приятным бонусом. Но, не учитывая всех факторов риска и не выделяя достаточно времени на проведение тестов, мы с большой вероятностью получим проваленный дедлайн.
Назову лишь некоторые последствия несоблюдения сроков:
- выплата денежной компенсации заказчику за срыв сроков;
- потеря репутации (а в сфере IT любая информация, особенно негативная, как эпидемия разносится по всем доступным каналам);
- потеря клиентов.
Всех этих неприятностей можно избежать с помощью тщательного анализа всех возможных рисков и планомерного расчета достаточного времени на тестирование проекта.

Обсудим ваш проект? Заполняйте форму!











