
Материал основан на реальном проектном опыте.
Для начала скажем несколько слов о проекте. Существует сайт букмекерской конторы для принятия ставок онлайн. До начала работ по автоматизации каждый ручной сет регрессионных тестов занимал около двух дней, релизы проводились примерно раз в неделю. Главным ожиданием заказчика от автоматизации было максимально возможное покрытие регресса автотестами, а также ускорение этого процесса.
Забегая вперед, отмечу, что сейчас релизы проходят каждый день или через день, а ручная часть тестов (то, что оказалось невозможно автоматизировать по тем или иным причинам) занимает примерно столько же времени, что и прогон автотестов с просмотром результатов.
Данные для основного функционала – принятие ставок – представляют собой список матчей различных видов спорта, обновляющийся в реальном времени по web-сокету:
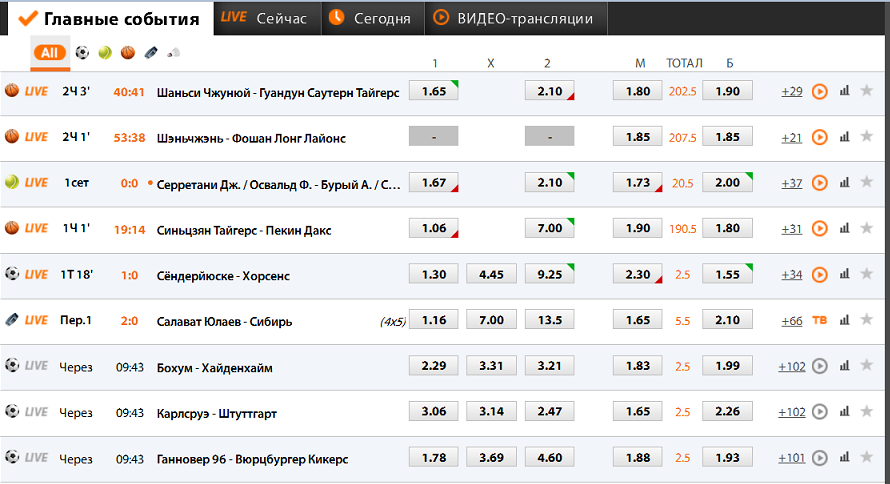
В указанных данных можно выделить два главных класса эквивалентности событий: матчи, проводимые в данный момент времени (Live), и матчи, которые еще не начались (Prematch). У этих классов отличаются некоторые поля в таблице матчей. При этом они по-разному обрабатываются сервером. Конечно, для каждого события существуют еще и кнопки с коэффициентами на различные исходы матча (например, первая кнопка означает победу первой команды в основном времени матча).
По клику на картинку откроется полная версия
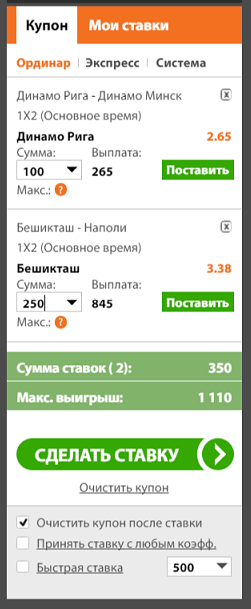
По клику на кнопку соответствующие маркеты (исходы события) добавляются в купон, в котором можно сделать различные варианты ставок: отдельно по одному (ординар) или по нескольким (экспрессы и системы) вариантам компоновки событий. После принятия ставка попадает в историю ставок. Это и есть функционал сайта.
Основная сложность при написании тестов для таких исходных данных заключается в том, что данные эти полностью динамические и меняются в реальном времени. Нельзя найти подходящий матч и использовать его в тестах постоянно, нужен некий механизм поиска при каждом запуске. Второй важный момент – нужных данных может не быть в принципе. К примеру, соревнования по некоторым видам спорта не проводятся в то или иное время года, матчи могут не сопровождаться видеотрансляцией и т. д.
Как работать в тестах с динамическими данными
Особенность тестирования динамических данных заключается в следующем: подходящие данные нужно найти в самом начале теста и далее работать с ними на всех этапах проверок. Как правило, они представляют собой некий список, оформленный в явном (например, выпадающий список) или неявном виде (например, колонка таблицы), который можно собрать с помощью одного локатора. Далее по тексту статьи будут встречаться фрагменты кода на Java с использованием стандартного Selenium 2.0 без дополнительных надстроек.
Самый простой вариант событий – это когда нас устраивают абсолютно любые данные и дополнительная фильтрация не нужна. Мы просто собираем их в список по локатору:
public List<WebElement> getListOfLiveEvents() {
return driver.findElements(liveEvents);
}
Так получается список интересующих нас элементов, с которым уже можно работать, просто запрашивая их по порядковому номеру.
Но что же делать, если нам нужно учесть сразу несколько элементов, а получить их в полном объеме затруднительно? Если повлиять на тестовые данные невозможно (как в случае с этим проектом), то, к сожалению, тест завершится ошибкой. И останется только выдать информативное сообщение о случившемся. Поэтому все тесты в проекте с данными, которых «может не быть», содержат проверку следующего вида:
List<WebElement> liveEventsWithBets =
mainPageMobile.getListLiveEventsWithBets();
assertTrue(«Для этого теста необходимо минимум 2 LIVE
события. Actual: « + liveEventsWithBets.size(),
liveEventsWithBets.size() >= 2);
Как провести фильтрацию
Организовать дополнительную фильтрацию данных при необходимости можно двумя методами:
- фильтрация на этапе поиска по локатору;
- фильтрация по уже сформированному списку сложных элементов, содержащих внутри себя другие элементы.
С локатором все достаточно просто. В качестве примера приведем xpath, в котором учитывается, что нам нужны кнопки коэффициентов с определенными свойствами (победа первой команды) и не нужны заблокированные кнопки:
//a[not(contains(@class,’locked’))][not(contains(@class,’hid
den’))][@data-ng-bind=’event.mainLines[1][0][0].value’ or
@data-ng-bind=’event.mainLines[2][0][0].value’]
Если уж мы заговорили про xpath, очень полезной штукой для поиска нужных элементов являются его оси. Ниже приведен уже встречавшийся нам ранее локатор для сбора списка Live-событий:
By liveEvents = By.xpath(«//img[@data-ng-if=’::event.isLive’]//ancestor::div[contains(@class, ‘l-events-event’)]»);
Таким образом мы привязываемся к желтой картинке LIVE (она видна на первом скриншоте в статье, у всех верхних Live событий). И возвращаясь по оси предков, получаем целиком весь div события.
Второй метод сложнее, но зато с его помощью можно организовать и более сложную фильтрацию. Мы воспользуемся такой возможностью xpath как относительный поиск элемента. Относительные локаторы обязательно должны начинаться с точки. Тогда поиск будет осуществляться от родительского элемента, для которого мы вызвали findElement:
public List<WebElement> getListLiveEventsWithBets() {
List<WebElement> eventList = getListOfLiveEvents();
List<WebElement> resultList = new ArrayList();
for (int i=0; i<eventList.size(); i++) {
if(eventList.get(i).findElements(
eventsButtonsNotLockedNotHidden).size()!=0) {
resultList.add(eventList.get(i));
}
}
if (resultList.size()==0) {
Assert.fail(«Нет доступных live событий со ставками»);
}
return resultList;
}
Суть этого метода в получении только тех Live-событий, у которых есть незаблокированная кнопка для ставки. Мы получаем изначальный список Live-событий уже знакомым нам методом getListOfLiveEvents(), а затем в цикле ищем доступную кнопку внутри этих элементов. Если поиск findElements(eventsButtonsNotLockedNotHidden).size() возвращает больше 0 элементов, мы записываем соответствующий родительский элемент в результирующий список. В противном случае у такого события нет доступных кнопок, и мы просто переходим к следующей итерации цикла поиска.
Можно выполнить также несколько фильтраций в одном методе, сделав еще один подобный цикл перед возвратом результирующего списка, но уже с поиском другого элемента. Если же нам нужны родительские элементы БЕЗ какого-то элемента внутри, то достаточно просто заменить в поиске size()!=0 на size()==0.
Недостатком этого метода, по сравнению с первым, является большое количество выполнений тяжелой операции findElements, что довольно серьезно снижает производительность. Следовательно, нужно стараться по возможности найти необходимые элементы за один раз.
Как сделать быстро
Что же касается упомянутого в заголовке статьи обещания «сделать быстро», то попробую дать несколько советов, следуя которым, можно уже на первых этапах получить пользу от автоматизации:
- Сначала автоматизируйте сценарии, которые можно описать быстро, используя готовые средства библиотеки или самого языка. Например, возвращаясь к этому проекту, два динамических списка можно сравнить через containsAll: (currentEventWinnersList.containsAll(winnersInSystemList). Написание сложных кастомных проверок и прочие «велосипеды» лучше отложить на более поздний срок. Это никак не повлияет на общий объем работы. Но затратив минимальное время, на выходе вы уже получите работающие тесты.
- Не бойтесь проходить тест по определенному сценарию даже без непосредственных проверок. Нажатие кнопки или переход на другую форму тоже является проверкой, хоть и неявной. Если что-то пойдет не так, вы, скорее всего, получите не «красивую ошибку», а какое-либо из исключений веб-драйвера, но зато и такая ошибка не пройдет незамеченной.
- Начинайте тестовые прогоны как можно раньше. Даже если есть какие-то проблемы с системой непрерывной интеграции, тесты вполне успешно можно прогонять локально, пока это не занимает много времени. При этом вы уже начнете получать пользу от запусков в виде найденных дефектов и будете стабилизировать и отлаживать свежие тесты по ходу дела.
Вывод
На данный момент тестовый проект насчитывает порядка 360 небольших и не зависящих друг от друга тестов как для обычной web-версии сайта, так и для мобильной. Время на регрессионные тесты значительно сокращено: с 2 рабочих дней до 2-3 часов. Заказчик имеет возможность выпускать релизы приложения каждый день, как и хотел. Для нас же это хороший и интересный опыт, а также возможность поддерживать и расширять тестовый проект. Ведь в таком динамично развивающемся продукте и автотесты должны актуализироваться соответственно.

")










[…] […]