Еще несколько лет назад к организации автоматизированного тестирования предъявлялось, по сути, лишь одно требование — исключить из большинства рутинных проверок труд человека. Активнее всего автоматизацию внедряли крупные компании, для которых производительность и скорость прохождения тестов редко являлись критическими показателями. Они без особых проблем могли «залатать» деньгами любую дыру в структуре тестов, подключив несколько дополнительных мощных серверов или расширив парк тестовых устройств.
Но рынок быстро меняется: число профессиональных автоматизаторов растет с каждым днем, поэтому не удивительно, что у многих QA-компаний появились выгодные предложения для среднего и малого бизнеса. Сегодня заказать создание 100-200 автотестов могут позволить себе владельцы практически любого небольшого приложения или сервиса. А вот заставить их работать эффективно, не «проглатывая» дорогостоящие ресурсы и не тратя десятки часов на выполнение, — и есть настоящий вызов. В этой статье мы поделимся двумя историями из нашей борьбы за производительность, не упуская трудностей, с которыми столкнулись во время путешествия сквозь мрачный лес прожорливых автотестов.
История первая: придаем ускорение
Представьте ситуацию. Есть десктопное приложение, для которого написано около 150 автотестов. Срок их выполнения — чуть больше восьми часов, или целый рабочий день. Звучит неплохо: на десктопных приложениях кейсы всегда выполняются довольно медленно. Наверное, этого объяснения вполне бы хватило, чтобы двигаться дальше, если бы не одна деталь: кейсы параллельно выполняются сразу на девяти агентах! И вот теперь восемь часов кажутся запредельным сроком для такого объема тестирования.
Первое, что мы сделали, — собрали статистику по самым времязатратным кейсам (попросту говоря, узнали, кто тут слишком много кушает). Так у нас появилась подборка из 30 тестов, на выполнение которых уходило от 10 до 20 минут. После этого мы определили ключевую задачу: оптимизировать логику и структуру «медленных» тестов таким образом, чтобы сценариев, выполняющихся дольше 10 минут, либо вообще не осталось, либо их число значительно сократилось. Идеалисты по натуре, мы верили, что сможем добиться первого варианта. Не станем томить: хэппи-энда не будет, не добились.
Но не станем забегать вперед, а лучше покажем план наших действий:
- Отметили кейсы, выполняющиеся дольше 10 минут.
- Для каждого из них выделили сущности, создаваемые в процессе работы.
- Пришли с этими данными к аналитикам и вместе разделили их на два типа: основные и вспомогательные.
- Забежали в подземелье с огнедышащими REST-специалистами, которые помогли нам разложить все кейсы по трем коробкам.
В первую коробку отправились те тесты, для которых второстепенные сущности можно создать с помощью REST-сервиса. Это дало значительное ускорение и не потребовало сложной магии. Во вторую коробку отправились тесты, работающие с разнообразными формами. Тут мы решили повернуть эволюцию вспять и перешли на низкоуровневое взаимодействие с компонентами. В последнюю, самую нелюбимую коробку, отправилось 4 кейса, от оптимизации которых нам пришлось отказаться. Они долго выполнялись не из-за проблем с кодом или его структурой, а из-за особенностей работы самого приложения. Так нам пришлось смириться с тем фактом, что довести до идеала все кейсы не получится.
Почему REST-сервис?
Во-первых, предусловия для тестов уже создавались REST-сервисом. Увидев это, мы поняли, что, слегка переработав структуру кода, сможем создавать сущности по мере прохождения самих кейсов. Это высвободило дополнительные ресурсы, в том числе и временные. Тем более что для этих тестов было важно, чтобы вспомогательные сущности создавались не в самом начале, а по мере продвижения по тест-кейсу. Во-вторых, часть сущностей мы реализовали с нуля, до этого мы не создавали их для предусловий. Может, и не звучит как нечто выдающееся, но с практической точки зрения дает большой прирост производительности. Поэтому если вы используете в том или ином виде REST-сервис, то подумайте, как еще можно использовать его при оптимизации ваших тестов.
Оптимизируете формы — решите большинство проблем
Не важно, сколько форм в вашем приложении, каждая из них — потенциально «узкое» место всей системы. Для того чтобы понять, какие из них самые ресурсоемкие, мы замерили время отработки методов в каждой конкретной форме. Это позволило выделить лишь те из них, которые гирями тянули все тесты в пучину бесконечного выполнения. Уже этого будет достаточно, чтобы получить ощутимый рост в скорости. Но не стоит останавливаться: проанализируйте работы с каждым конкретным элементом формы. Это позволяет выделить группу элементов, поиск которых производится неоправданно долго. И именно с этими элементами стоит плотнее всего работать. В нашем случае мы переписали метод поиска при помощи низкоуровневых компонентов фреймворка.
И вот они — результаты
Увы, у нас было не так много времени, чтобы полноценно оценить всю проделанную работу и поделиться с вами красивыми графиками, поэтому расскажем о результатах первого запуска обновленного тестового набора. В среднем проблемные тесты ускорились на 40%. Теперь они выполняются меньше 10 минут. Здесь должны греметь фанфары, но наши вечно чем-то недовольные аналитики не позволяют слишком уж задирать нос. Впрочем, мы и сами уверены, что можем превзойти достигнутые результаты. Есть в наборе и тесты, которые стали работать еще быстрее. К примеру, по одному из кейсов мы зафиксировали ускорение на 68%: было 19 минут, стало всего 6.
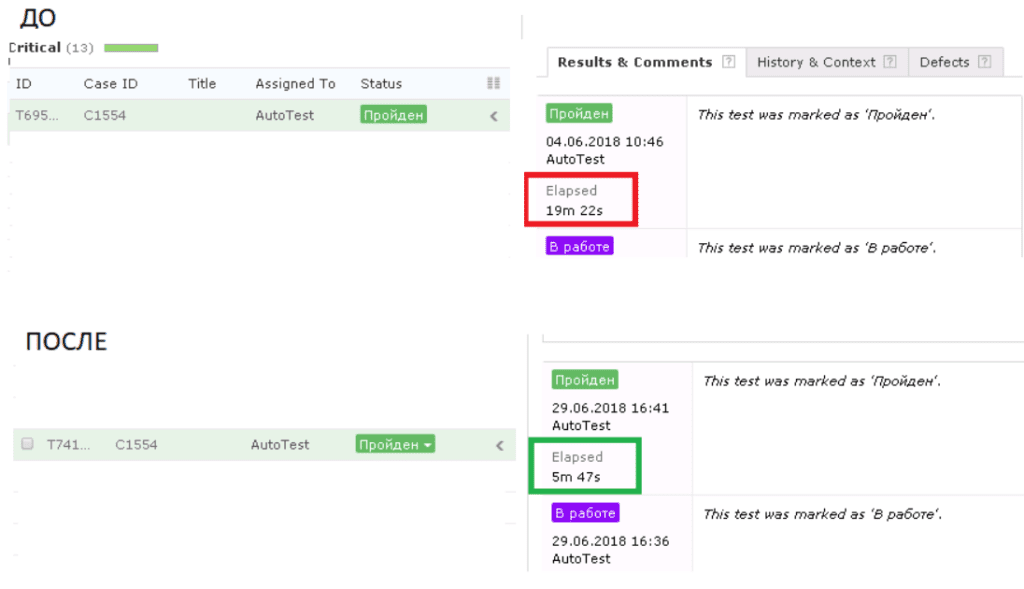
Собираемся ли мы останавливаться? Знаете, да. Это, пожалуй, самый важный секрет: после первой волны оптимизации нужно притормозить и собрать новый набор статистических данных, проработать дальнейший план действий. Это позволит при следующей оптимизации добиться более высоких показателей, чем если тут же попытаться разогнать автомобиль, который и так уже довольно быстро едет. Уверены, что время общего запуска продолжит сокращаться и дальше. Главное — смотреть на картину чуть шире и наконец-таки перестать думать о тех четырех кейсах, которые мы оставили за оптимизационным бортом.
История вторая: когда из ресурсов — только вера и смекалка
Автоматизация на иностранной рекламной площадке в условиях сильно ограниченных ресурсов — задача не из простых, но трусы, как известно, не играют в хоккей. А мы не трусы! Да и площадка не из пугливых: ее основная задача — запуск продуктивных рекламных кампаний на различных ресурсах с последующим сбором статистики. И все это с помощью сложных, нетривиальных формул, которые дают возможность заказчику точно понять, насколько успешной была его реклама.
Звучит как настоящий рай для автоматизатора, если бы не три «но»:
- все тесты необходимо было параллелить в условиях крайне ограниченных ресурсов;
- несмотря на строгую экономию, тесты должны покрывать максимально разнообразные окружения, включая далеко не бюджетную MacOS со специфичным Safari;
- заказчик сам определил инструменты и решения, отказавшись от большинства классических решений.
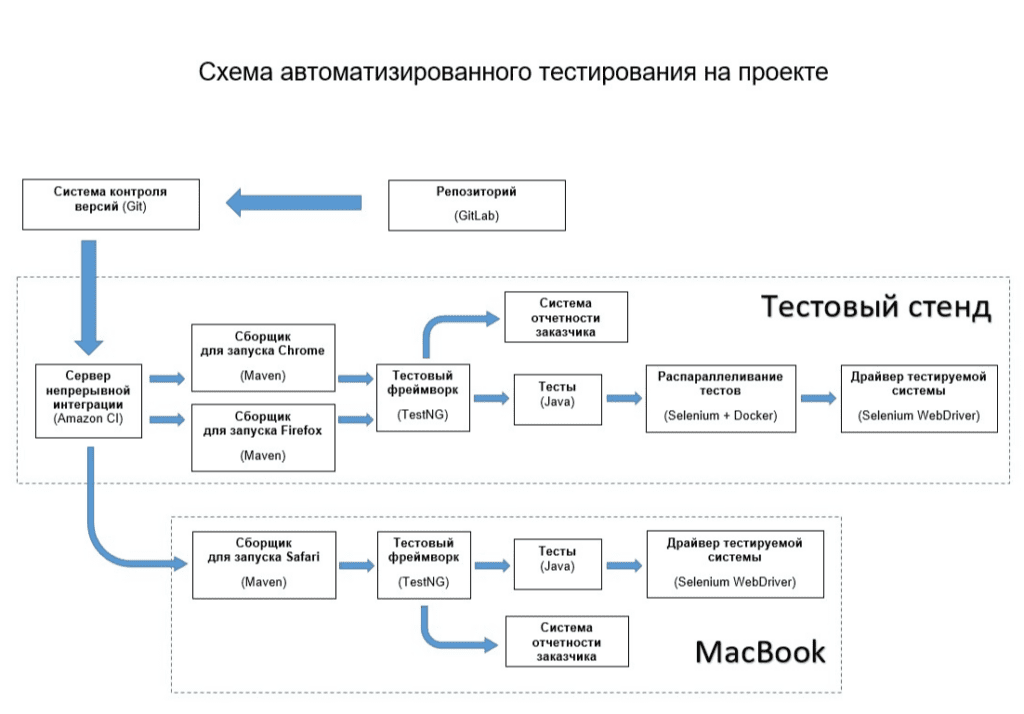
И вся эта инфраструктура должна быть готова к тому, чтобы отрабатывать колоссальный объем автотестов на стендах с очень, очень, ну очень ограниченными ресурсами. Перед тем как перейти к самому интересному, расскажу о нашем стеке: Java, Maven, TestNG, Selenium WebDriver, Selenide, CI Amazon.
Компромисс первый: пока, Selenium Grid!
Классический Selenium Grid требовал такого объема ресурсов, что нам пришлось отказаться от идеи параллелить тесты с его помощью. Мы выбрали другой способ: связку Selenoid и Docker-контейнеров. Это позволило нам запускать разные версии одного браузера. Чтобы реализовать это на практике, под каждый из браузеров мы сделали отдельную задачу в CI, а уже в рамках этой задачи запускали сборщик с указанием нужного браузера. В текущих условиях именно это решение оказалось наиболее стабильным, куда крепче, чем если бы мы занимались распараллеливанием на уровне TestNG.
Компромисс второй: никаких виртуальных MacOS
Пожалуй, самым оригинальным решением оказался полный отказ от запуска виртуальных машин под MacOS для тестирования в Safari. Вместо этого тесты запускаются из CI… на отдельном MacBook. Это и обеспечило крутой выхлоп по производительности, и укрепило стабильность всей системы. На тестовом стенде с установленной виртуальной MacOS мы бы и близко не подобрались к текущим результатам.
Компромисс третий: отделить данные от тестовой среды
Мы решили, что в условиях жесткой экономии ресурсов стоит отделить сами тесты от данных, с которыми они работают. Для этого мы развернули базу данных MongoDB на отдельной машине, к которой и обращается тестовая версия продукта как к рабочему варианту БД.
Первые результаты
Анализ системы показал, что она полностью готова к запуску огромного количества автотестов. Для построения всей тестовой инфраструктуры мы использовали несколько действительно слабых в плане ресурсов машин, но, правильно соединив их, смогли обеспечить максимальную производительность всей системы. И это важно, учитывая, что зима близко… Простите. И это важно, учитывая, что на нас надвигается целая лавина тестовых сценариев.
За время работы над этими двумя проектами мы поняли главное: не имеет значения, какого размера бизнес наших клиентов, важно, что мы должны понять, как помочь им реализовать свои идеи в рамках тех ресурсов, которыми они обладают. Потому что легко запускать автотесты, когда у тебя есть несколько десятков свободных мощных машин. А попробуй на чайнике!
На сегодня — все!
До встречи в блоге «Лаборатории качества».











